


by Paul C. Zikopoulos and Roman B. Melnyk
This article outlines range-clustered table (RCT) support in the IBM DB2 Universal Database (DB2 UDB) products as of Version 8.1.4. RCTs represent a new table type that is supported through the ORGANIZE BY KEY SEQUENCE clause on the CREATE TABLE statement.
This new feature can dramatically improve performance for some workloads. RCTs exploit a method of organizing rows in a table that allows for very fast direct access to any given row, or set of rows, without indexes. This is accomplished through sequential numeric primary key values (for example, an employee ID). Transaction processing applications often generate sequential numbers for use as primary key values; such databases will benefit the most from implementing RCTs.
The database manager leverages the sequential nature of the key column values in an RCT to determine the location of any row in the table. Because the data is always kept in a specific order, the location of a particular row is based on its sequence number, which is logically mapped to a row number.
To qualify as an RCT, a table must have key values that are:
- Unique
- Not null
- Of type SMALLINT, INTEGER, or BIGINT
- Monotonically increasing
- Within a predetermined range for each column in the key
DB2 UDB-supported table types
DB2 UDB now supports four table types: regular, append mode, multidimensional clustered (MDC), and range-clustered. Each table type has characteristics that make it useful when working in a particular business environment. The matrix in Figure 1 compares and contrasts the four table types.
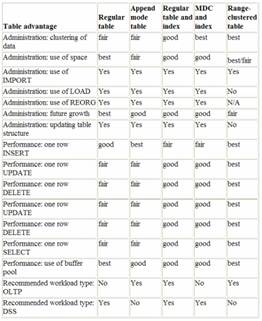
Figure 1. A comparison of the benefits offered by each of the four supported table types. Range-clustered tables offer superior performance.
As a general rule of thumb:
- Regular tables with indexes are general purpose tables that represent a good starting choice. If your data will be loosely clustered (not monotonically increasing), consider using a regular table and indexes.
- Append mode tables are suitable if you are only adding new data and retrieving existing data, such as is the case in a banking scenario, in which changes to an account are tracked through debits, credits, and transfers, and customers can review the history of changes to their accounts.
- Multidimensional clustered tables are used in data warehousing and large database environments. Clustering indexes on regular tables support one-dimensional clustering of data, but MDC tables provide the benefits of data clustering across more than one dimension.
- Range-clustered tables are useful when the data is tightly clustered across one or more columns in the table. The smallest and largest values in the columns define the range of possible values. You use these columns to access rows in the table.
Advantages of using range-clustered tables
RCTs can result in significant performance advantages during query processing because fewer input/output (I/O) operations are required to complete transactions. RCTs require less cache buffer allocation because there are no secondary objects to maintain. Because RCTs do not require indexes, DBAs that utilize these objects will find savings in storage as well.
RCTs also require fewer locks. With regular tables, rows are locked to ensure that only one application or user has access to a row or group of rows at any given time. With RCTs, “discrete locking” is used instead of key and next-key locking. This method locks all rows that are affected by, or that might be affected by, a requested operation. The number of locks that are obtained depends on the isolation level. Qualifying rows in the RCT that are currently empty, but that have been preallocated, are locked. This avoids the need for next-key locking.
Locking only affected rows can actually result in increased concurrency. Consider a table T1 with seven rows (1, 2, 3, 4, 7, 8, and 9) and repeatable read (RR) isolation. If T1 is an RCT, the following actions could happen concurrently:
Application 1 executes the following query and locks rows 7, 8, and 9 in share (S) mode:
select * from T1 where PrimaryKeyvalue >= 7
and PrimaryKeyvalue <= 9
Application 2 executes the following insert operation to add row 6, and locks row 6 in exclusive (X) mode:
insert into T1 values (6)If T1 is a regular table with a Type 1 index, Application 2 will not only lock row 6, but will try to lock the next row (in this case, row 7) in exclusive mode, thereby conflicting with Application 1. As long as you do not have any overflows, RCT concurrency is always at least as good as the concurrency that can be achieved with indexes, and sometimes a bit better. The way we like to think about it is that RCT concurrency is equivalent to a Type 2 index with every non-existent row being pseudo-deleted. For insert and 1-row delete operations, RCTs do take fewer locks than would a table with an equivalent index. For selects in which every possible selected value exists, RCTs take the same number of locks, and for selects in which certain possible values have not yet been inserted, RCTs take more locks than would a table with an equivalent index.