
Introduction
One of the most interesting features in SQL Server 2008 is
filtered indexes. Let’s start with a quick explanation and then dig into the
details and results.
A filtered index is simply an index with a WHERE clause. For
example, if you have a table where a date is NULL in 90% of the records but you
need to be able to find only records with a non-NULL date, a filtered index will
have only the 10% that are not NULL.
It can be very useful for saving space, saving index
maintenance costs, and making queries run faster. However, it is important to
understand under what circumstances it will make your query faster.
Test Setup
Download the files for this article.
Table
This test uses one simple table to demonstrate filtered
indexes.
CREATE TABLE Perf.[Card] (
CardID int NOT NULL IDENTITY(1,1),
CardNumber bigint NOT NULL,
SecurityCode smallint NOT NULL,
SecureString char(36) NOT NULL,
ControlCase10 int NOT NULL,
ControlCase100 int NOT NULL,
ControlCase1000 int NOT NULL,
ControlCase10000 int NOT NULL,
CONSTRAINT PK_Card PRIMARY KEY CLUSTERED (CardID)
)
GO
The “ControlCasen” columns are set up to allow a tightly-controlled
set of columns where some percentage of the rows match a WHERE clause. For
ControlCase10, 1 in 10 columns have the matching value; for 100, 1 in 100 and
so on.
Indexes
This table has multiple filtered and non-filtered indexes.
Filtered (1 in 10)
…ControlCase10_1 ON … (ControlCase10)
WHERE ControlCase10 = 1
Non-filtered
…ControlCase10 ON … (ControlCase10)
Filtered (1 in 100)
…ControlCase100_1 ON … (ControlCase100)
WHERE ControlCase100 = 1
Non-filtered
…ControlCase100 ON … (ControlCase100)
Filtered (1 in 1,000)
…ControlCase1000_1 ON … (ControlCase1000)
WHERE ControlCase1000 = 1
Non-filtered
…ControlCase1000 ON … (ControlCase1000)
Filtered (1 in 10,000)
…ControlCase10000_1 ON … (ControlCase10000)
WHERE ControlCase10000 = 1
Non-filtered
…ControlCase10000 ON … (ControlCase10000)
The reason for having a non-filtered index matching each
filtered index is to give the optimizer choices when querying a specific column
value.
The test script loads the table with 1,000,000 rows. Below, we’ll
see information about index size and performance.
Index Sizes
If there is a non-filtered index for a 1,000,000-row table
and a filtered index for that same table where the filter eliminates 90% of the
rows, we would expect the size of the filtered index to be roughly 10% of the
non-filtered index.
Here are some real results of index sizes:
Sorted by Index Name
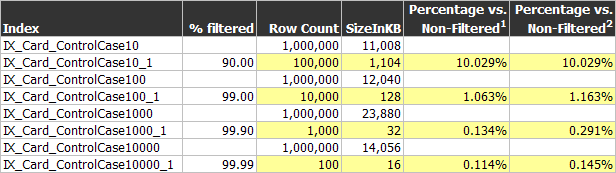
1 Comparing the filtered
size vs. its corresponding non-filtered size (e.g. 16 / 14056 =
0.00114).
2 Comparing the filtered
size vs. the lowest non-filtered size (11,008) for each calculation
(e.g. 16 / 11008 = 0.00145). This produces more-consistent results.
Sorted by Index Size (Grouped by
Filtered/Non-Filtered)
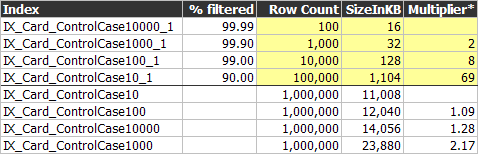
* The “Multiplier” column shows the
size multiplier compared to the smallest index size for that category (filtered/non-filtered).
It is interesting to see that the size of the four
non-filtered indexes varies widely, even though they all index exactly 1,000,000
rows. I reran these tests multiple times and got the same results.
Notice the sizes of the filtered indexes. We’re always happy
to see a pattern, and even happier when we see such a consistent pattern.
Query Optimizer Choices
When we run queries against the Card table utilizing these
“control” columns, which index does the optimizer choose? Well, it depends.
SELECT COUNT(*)
We know that there are 1,000,000 rows in the Card table. In the
first three of these cases, the optimizer chose the filtered index. In the last
case, it chose the non-filtered index.
SELECT COUNT(*) AS Ct FROM Perf.[Card] WHERE ControlCase10 = 1
Logical Read Count: 138
SELECT COUNT(*) AS Ct FROM Perf.[Card] WHERE ControlCase100 = 1
Logical Read Count: 16
SELECT COUNT(*) AS Ct FROM Perf.[Card] WHERE ControlCase1000 = 1
Logical Read Count: 4
SELECT COUNT(*) AS Ct FROM Perf.[Card] WHERE ControlCase10000 = 1
Logical Read Count: 3
In the last case, since there are only 100 qualifying
records, it looks like the optimizer chose a “good enough” plan. The query only
requires three logical reads with the unfiltered index. Using an index hint to
force it to use the filtered index only drops the logical read count to two.
Using an index hint to force it to use the PK causes 9,516 logical reads.
SELECT CardID
When all we have in the SELECT list is the PK, the optimizer
again uses the filtered indexes for the first three queries and the
non-filtered index for the fourth.
SELECT CardID FROM Perf.[Card] WHERE ControlCase10 = 1
Logical Read Count: 138
SELECT CardID FROM Perf.[Card] WHERE ControlCase100 = 1
Logical Read Count: 16
SELECT CardID FROM Perf.[Card] WHERE ControlCase1000 = 1
Logical Read Count: 4
SELECT CardID FROM Perf.[Card] WHERE ControlCase10000 = 1
Logical Read Count: 3
In the last case, hinting the filtered index again drops the
logical read count to two. Hinting the PK has the same result as before (9,516
logical reads).
So, SELECT COUNT(*) and SELECT CardID (the PK) have exactly
the same results.
SELECT CardNumber
When we query a column that is not part of the PK, the
optimizer has to choose between scanning the PK (where the physical pages are
right there) and scanning the nice, compact filtered index and incurring the
cost of the bookmark lookup to get the value of the requested column.
SELECT CardNumber FROM Perf.[Card] WHERE ControlCase10 = 1
Logical Read Count: 9,492
SELECT CardNumber FROM Perf.[Card] WHERE ControlCase100 = 1
Logical Read Count: 9,516
SELECT CardNumber FROM Perf.[Card] WHERE ControlCase1000 = 1
Logical Read Count: 3,075
SELECT CardNumber FROM Perf.[Card] WHERE ControlCase10000 = 1
Logical Read Count: 317
Here, the optimizer chose to scan the PK in the first two
cases and used the filtered index in the last two cases. As an example of how
the optimizer made the right choice, hinting the filtered index for the first
query bumps the logical read count from 9,492 to 306,695!
Note that the first two plans use parallelism, and this is
running on a very strong box – four 64-bit dual-core processors and 64 GB RAM.
As always, your mileage may vary, so test it in your own environment.
Combining Filtered Indexes with INCLUDE
Now we’ll see the ultimate way to pull all this
together. Knowing we want to read the CardNumber column (which is not part of
the clustered PK), let’s add a set of INCLUDE indexes. Here is an example:
CREATE NONCLUSTERED INDEX <name>
ON Perf.[Card] (ControlCase100)
INCLUDE (CardNumber)
WHERE ControlCase100 = 1
CREATE NONCLUSTERED INDEX <name>
ON Perf.[Card] (ControlCase100)
INCLUDE (CardNumber)
So this one column (ControlCase100) now has four indexes:
- One without a filter
- One with a filter
- One without a filter but with an INCLUDE
- One with a filter and an INCLUDE
Let’s rerun the queries that read CardNumber and see what
the optimizer chooses and what the logical read counts are.
SELECT CardNumber FROM Perf.[Card] WHERE ControlCase10 = 1
Logical Read Count: 237 (vs. 9,492)
SELECT CardNumber FROM Perf.[Card] WHERE ControlCase100 = 1
Logical Read Count: 26 (vs. 9,516)
SELECT CardNumber FROM Perf.[Card] WHERE ControlCase1000 = 1
Logical Read Count: 5 (vs. 3,075)
SELECT CardNumber FROM Perf.[Card] WHERE ControlCase10000 = 1
Logical Read Count: 3 (vs. 317)
Here, the results are similar the COUNT(*) and CardID
queries: the first three used the filtered/include index, and the fourth query
used the non-filtered/include index–but it chose the INCLUDE index in every
case.
If we hint each of the indexes on the ControlCase1000
column, here are the logical read results:
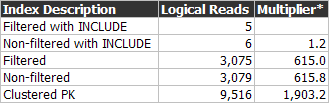
* The “Multiplier” column compares
the logical read count to the lowest count (5).
Conclusion
Using filtered indexes can significantly speed up your
queries in some cases. The best way to use them is to add INCLUDE columns to
cover your most-used queries.
Download the files for this article.
Thoughts or comments? Drop a note in the forum or
leave a comment.
Reference
-
Filtered
Index Design Guidelines from SQL Server Books Online -
CREATE
INDEX from SQL Server Books Online -
Exploring
SQL Server’s Index INCLUDEs at Database Journal