


Rob Gravelle explores the pros and cons of normalization with a particular focus on the ramifications of third normal form normalization on data extraction by SELECT query.
Extracting data from a normalized database structure requires special care. This holds especially true where tables share a many-to-many relationship. In this article, we’ll be looking at the pros and cons of normalization with a particular focus on the ramifications of third normal form normalization on data extraction by SELECT query.
A Crash Course on Normalization
Among the most important tenets of database design, as influenced by the work of E.F. Codd, is that a database should at least fulfill the conditions of third normal form (3NF).
|
|
Normalization is the process of applying a series of rules to ensure that your database achieves optimal structure. Each normal form is a progression of these rules as successive normal forms achieve a better database design than the previous ones did. Although there are several levels of normal forms, it is generally sufficient to apply only the first three levels of normal forms. They are described in the following paragraphs. |

First Normal Form
To achieve first normal form, all columns in a table must be atomic. This means, for example, that you cannot store first name and last name in the same field. The reason for this rule is that data becomes very difficult to manipulate and retrieve if multiple values are stored in a single field.
Another requirement for first normal form is that the table must not contain repeating values. An example of repeating values is a scenario in which Item1, Quantity1, Item2, Quantity2, Item3, and Quantity3 fields are all found within an Orders table.
Second Normal Form
To achieve second normal form, all non-key columns must be fully dependent on the primary key. In other words, each table must store data about only one subject.
Third Normal Form
To attain third normal form, a table must meet all the requirements for first and second normal form, and all non-key columns must be mutually independent. This means that you must eliminate any calculations, and you must break out data into lookup tables.
The Good, the Bad, and the Ugly
First, the good. Normalization does provide many benefits:
- It provides indexing in the form of clustered indexes.
In most cases, the creation of a clustered index will speed up data access and may increase insert, update, and delete performance. - Minimizes modification anomalies.
Modification anomalies arise when data is inserted, updated, or deleted, and information is lost in unexpected ways. - Reduces table/row size.
By removing duplicate data, we conserve disk space and increase the amount of row space available for other fields. - Enforces referential integrity.
Referential integrity problems usually manifest themselves as an inability to extract important data or relate information from one table with data in another table because there is nothing on which to join the two tables.
And now for the bad and the ugly:
- The more optimized a database is, the more effort and time it takes to retrieve data.
You see, database normalization is aimed at storing data in the most optimal manner – preserving referential integrity, as well as removing data redundancy, thus making inserts, updates and deletes as efficient as possible. But this is just looking at one part of the picture. The tradeoff is this:Optimizing a database for storage automatically makes it unoptimized for retrieval.
- Numerous and complex table joins.
Database normalization comes with a price. A drawback to having a highly normalization database structure is that you may need a large number of joins to pull back the records the application needs to function. The fact that the database is usually an application performance bottleneck only aggravates the problem. This is especially apparent in environments in which many concurrent users access the database.
A Practical Example
The following UML diagram, which appears on Jeff Atwood’s Coding Horror site, represents a user profile on a typical social networking site:
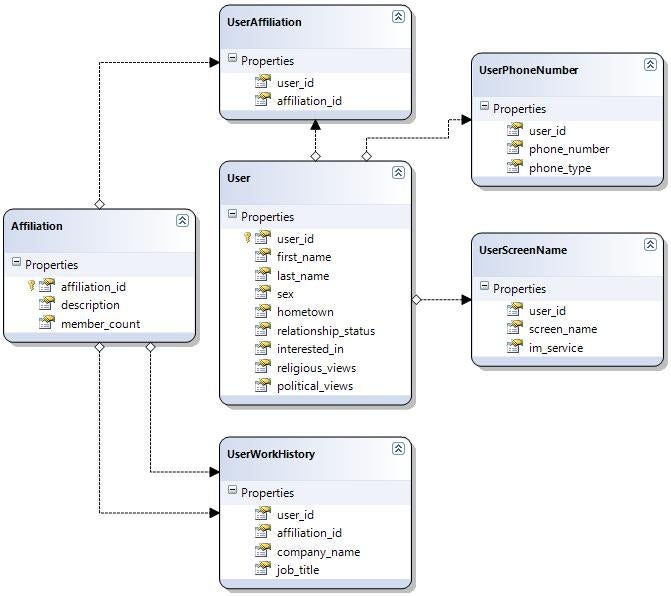
This is the kind of information you see on the average profile on Facebook. With the above design, it takes six SQL join operations to access and display the information about a single user. This makes rendering the profile page a fairly database intensive operation. This issue is compounded by the fact that profile pages are the most popular pages on social networking sites.
select * from Users u
inner join UserPhoneNumbers upn on u.user_id = upn.user_id
inner join UserScreenNames usn on u.user_id = usn.user_id
inner join UserAffiliations ua on u.user_id = ua.user_id
inner join Affiliations a on a.affiliation_id = ua.affiliation_id
inner join UserWorkHistory uwh on u.user_id = uwh.user_id
inner join Affiliations wa on uwh.affiliation_id = wa.affiliation_id
The Three-way Join
The joining of tables that share a many-to-many relationship is the most complex. That’s because of the third junction table that links the two related tables. To extract the data from these tables requires something called a three way join. Here’s a three way query that retrieves data from the employees, shops, and junction shops_employees tables where employees can work for several shops at once and shops can have many employees working there:
select *
from employees as e,
shops_employees as se,
shops as s
where e.id = se.employee_id
and se.shop_id = s.shop_id;
Notice how the employees table links to the shops_employees table through the employee id and the shops_employees table in turn links to the shops table through the shared shop_id field.
Handling Optional Foreign Keys
There is some debate as to whether foreign keys should ever be null. Conceptually, there is nothing to inherently prevent the existence of null foreign keys. From the standpoint of a data-driven application, which interacts with a database, the determining factor is whether or not the related object, that is the owner of the foreign key, is optional or not. For instance, one form might contain information about individuals associated with various organized crime organizations. The same individual can be a part of several organizations, or none at all, in which case, there will be no record for that client in the organized crime organization or junction tables.
To perform a lookup on clients that displays relevant organized crime group associations, we have to take special care to not filter out clients who have no such association because
RECORDS WITH NULL FOREIGN KEYS WILL NOT BE RETURNED BY THE QUERY USING REGULAR JOINS
Here are some modified employees and shops tables that I have been referring to in my last several articles. I changed their relationship from one-to-many to many-to-many by allowing employees to work for more than one shop. This change would better record the temporal data of an employee that changed shops over the course of their employment.
The employees table
|
id |
gender |
name |
salary |
|
1 |
m |
Jon Simpson |
4500 |
|
2 |
f |
Barbara Breitenmoser |
(NULL) |
|
3 |
f |
Kirsten Ruegg |
5600 |
|
4 |
m |
Ralph Teller |
5100 |
|
5 |
m |
Peter Jonson |
5200 |
|
6 |
m |
Allan Smithie |
4900 |
The shops table
|
shop_id |
shop |
|
1 |
Zurich |
|
2 |
New York |
|
3 |
London |
The shops_employees table
|
shops_employees_id |
employee_id |
shop_id |
|
1 |
1 |
2 |
|
2 |
1 |
1 |
|
3 |
2 |
2 |
|
4 |
3 |
3 |
|
5 |
3 |
1 |
|
6 |
5 |
3 |
Using a straight join does not display all of the employees because Ralph Teller and Peter Johnson are not associated with any shop. Perhaps they are sales people who travel as part of their jobs.
select name,
gender,
shop
from employees as e,
shops_employees as se,
shops as s
where e.id = se.employee_id
and se.shop_id = s.shop_id;
Notice that Ralph Teller and Peter Johnson are missing from the results:
|
name |
gender |
shop |
|
Jon Simpson |
m |
New York |
|
Jon Simpson |
m |
Zurich |
|
Barbara Breitenmoser |
f |
New York |
|
Kirsten Ruegg |
f |
London |
|
Kirsten Ruegg |
f |
Zurich |
|
Peter Jonson |
m |
London |
To retrieve all of the employees, whether or not they are associated with any shops necessitates the use of Left Joins between the employees and shops_employees as well as the shops_employees and shops tables:
select emp.name,
emp.gender,
sh.shop
from employees AS emp
left JOIN shops_employees as se ON (emp.id = se.employee_id)
left JOIN shops as sh ON (sh.shop_id = se.shop_id)
order by emp.name,
sh.shop;
Now we get all of the employee information, including those with null shop_ids:
|
name |
gender |
shop |
|
Allan Smithie |
m |
(NULL) |
|
Barbara Breitenmoser |
f |
New York |
|
Jon Simpson |
m |
New York |
|
Jon Simpson |
m |
Zurich |
|
Kirsten Ruegg |
f |
London |
|
Kirsten Ruegg |
f |
Zurich |
|
Peter Jonson |
m |
London |
|
Ralph Teller |
m |
(NULL) |
There is a whole lot more to querying normalized database tables than we covered here today. Executing more complex queries and handling larger data sets call for more sophisticated strategies. You might be appalled to learn that one such strategy involves…gasp…denormalization! That would make one fine Halloween topic.