


A lot has been written about the “NoSQL” alternative as an alternative to SQL and other large database systems for a lighter, faster, cheaper alternative for the cloud. Most of these light weight database processors ignore data processing principles and lack the ability to turn data into information. This SQL trade-off may not be necessary.
There has been a lot written
about the “NoSQL” alternative in the press as an alternative to SQL and other
large database systems for a lighter, faster, cheaper, easier to add new data
types, and larger memory capacity alternative for the cloud. Most of these
light weight database processors do what they claim but at a cost of ignoring
data processing principles and lacking the ability to turn data into
information. This SQL trade-off may not be necessary. The solution is to take advantage
of ANSI SQL’s powerful
inherent full hierarchical processing capability as described previously in
this series of articles on SQL hierarchical processing.
- Hierarchical Structure Natural Benefits
- How SQL is Made to Perform Hierarchically
- Physical Hierarchical Structures Do Not Require Joining in SQL
- Hierarchical Optimization Can Produce Other Capabilities
- Easier More powerful Queries
- Replacing the Relational Engine with a Hierarchical Engine
- Automatic Parallel Processing
- Conclusion
Hierarchical Structure Natural Benefits
Hierarchical
structures are very unique not only in how well they organize data, but also in
how they naturally capture more meaning than is stored with the data. Even more
impressive is their ability to dynamically process this natural goldmine of
meaning in unlimited ways that further increases the value of the stored data.
With the increased use of hierarchical XML data structures today, there is an
incredible amount of unused data value potential available.
Hierarchical structures are easily built and expanded naturally
over time. Suppose we start building a hierarchical structure by creating and
populating node A over node B. Then at some point we add node C also directly
under node A and also start populating it. This is an example of reuse by
reusing the already existing node A and its data. We also know what nodes node
A has control over and how nodes B and C are related to each other. With the
addition of each new node, the data value will increase in a nonlinear fashion.
At this point, this multipath nonlinear hierarchical structure looks like the
one below in Figure 1.

How SQL is Made to Perform Hierarchically
Figure 1 shows an example of the
LEFT Outer Join defining a hierarchical structure with its syntax and also specifies
its hierarchical processing using its associated semantics (i.e. preserving A
over B and C). This is possible when the processing is limited to only SQL
hierarchical join operations. The LEFT Outer Join and its less used reversed RIGHT
Outer Join are the only join operations that perform hierarchically, so these
are the only join operations that can be used for hierarchical processing. INNER
joins and FULL joins are not allowed. By limiting processing to only
hierarchical joins, hierarchical operational principles come to the foreground
and totally control the processing. This is an example of less is more. This
is similar to structured processing where the GOTO statement is not allowed, enabling
more correct code and error detection with provable correct processing. With
hierarchical processing, this restriction allows for valid hierarchical assumptions,
which supported by hierarchical principles, can create new capabilities such as
performing hierarchical operations and optimization.
Physical Hierarchical Structures Do Not Require Joining in SQL
Figure
1 above showed an example of how a hierarchical structure is defined and
modeled in ANSI SQL using the LEFT Outer Join. The fully formed LEFT Outer Join’s
syntax and semantics together also specifies the hierarchical data structure’s
metadata. For SQL data, the LEFT Outer Join operation is executed by the SQL
processor to build the physical hierarchical structure from the logical relational
hierarchical structure. But with physical hierarchical structures such as XML, the
LEFT Outer Join execution can be eliminated because the hierarchical structure
is already in one piece. This allows it to be converted and placed directly into
the relational rowset without performing any join operations, but the
structured metadata in its defining LEFT Outer Join is still used for its SQL
hierarchical processing.
Hierarchical Optimization Can Produce Other Capabilities
Powerful
hierarchical optimizations dynamically tailor each query when executed so that
only the necessary nodes in the view are accessed based on the active query. Besides
limiting data access, this greatly reduces relational data explosions. This
makes any large view a global view with no overhead so that fewer views or even
a single view can be utilized. This means that users do not have to know what
view to use or have to be familiar with the structure. This makes SQL
processing more user friendly. These powerful hierarchical capabilities are
performed transparently by using SQL’s SELECT, FROM, WHERE and LEFT JOIN operations.
This means that nontechnical users can easily specify powerful hierarchical
queries using a simple standard ANSI SQL hierarchical processing subset.
Easier More powerful Queries
Most
applications can be designed or modeled hierarchically and can benefit from
principled hierarchical operations. We have shown that as a hierarchical
structure naturally grows larger in structure by adding additional nodes and
pathways over time, its inherent data value automatically increases nonlinearly
by the natural hierarchical data reuse. This also significantly increases the
number of possible new queries, further increasing the value of the data. In
addition, the naturally occurring data semantics existing between the
referenced pathways are used to process more powerful and accurate multipath
queries dynamically. This creates more meaning and value from the data than is
stored. This enables these multipath queries to answer these internally complex
queries automatically without requiring user navigation for hierarchical data,
even for XML.
Replacing the Relational Engine with a Hierarchical Engine
SQL’s
processing automatically supports full hierarchical processing, taking
advantage of all the powerful capabilities and principles that come with the
overlap of hierarchical and relational processing principles. Putting an ANSI
SQL relational interface over a hierarchical processing engine to replace the
relational engine should not be that difficult. This is possible because
hierarchical processing is a subset of relational processing. This enables SQL’s
hierarchical processing powerful and principled subset of relational processing
to be replaced with a simpler memory friendly powerful hierarchical engine that
can still fulfill the NoSQL capabilities mentioned above. Hierarchical engines
do not replicate data which avoids relational data explosions. They always
reflect the actual data exactly. In addition, performing joins of hierarchical
structure views is performed internally with a simple link operation instead of
expensive relational joins.
Automatic Parallel Processing
Hierarchical
structures’ natural parallel processing capabilities may be very useful in a
cloud environment by utilizing parallel processing’s dynamic memory utilization
and the cloud’s ability to service the request on demand and pay as you go
basis.
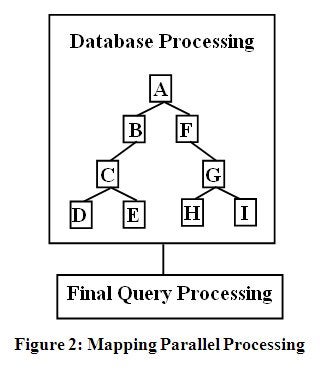
Hierarchical
data structures are naturally parallelizable. By examining the hierarchical
data structure with its nodes (or processing tasks) in Figure 2 below, it can
be seen how it naturally maps directly to the parallel pathways. The parallel
paths are: A/B/C; C/D; C/E; A/F/G; G/H; and G/I. In addition, their multiple
data occurrences at each node can be parallel processed too. This is a much
higher than normal level of parallelization possible.
Nodes
like C and G, which produce multiple pathways as shown in Figure 2 are natural sync
points for database processing. This means that all of their children and their
multiple occurrences must be processed under the same parent node data
occurrence before moving on. This is because moving to the next parent data node
occurrence before all its children are processed can lose database positioning
for the current parent’s physical database node occurrence. For example, if
node D completes before node E, node C must wait for node E to complete.
A
possible problem to full parallel processing of SQL’s hierarchical queries is
the Final Query Processing after the Database Processing completes, shown in
Figure 2. But it can be pipelined with the Database Processing. This means that
a new query can start processing while the Final Processing of the previous
query is operating. This helps with the overall throughput of the queries.
Since
hierarchical data processing can be highly processed in parallel automatically,
this makes it a good candidate for cloud processing with its unpredictable
dynamic memory utilization and increased throughput. For additional information
on parallel processing of hierarchical data see: http://www.devx.com/SpecialReports/Article/40939/1954.
Conclusion
This
article has shown that cutting back on database memory usage and the storage
footprint size does not have to result in giving up data processing principles,
the ability to turn data into information, ease of use, and the support of
advanced capabilities.