


This article covers multipath operations that require a different hierarchical logic than SQL naturally produced hierarchical processing. These include nonlinear data ordering, the renormalization of data to remove replicated data, and the processing of network structures.
This series of articles on ANSI SQL Hierarchical Processing Capabilities
has so far demonstrated the many inherent full hierarchical processing
capabilities that exist naturally in SQL. These have included: multipath
hierarchical processing; hierarchical
data mashups; hierarchical
data filtering; and hierarchical
data transformations. This article will cover those multipath operations
that require a different hierarchical logic than SQL naturally produced
hierarchical processing. These include nonlinear data ordering, the renormalization
of data to remove replicated data, and the processing of network structures.
- Hierarchical Data Relationship Review
- Ordering Out of Hierarchical Order Causes Problems
- Hierarchical Structure-Aware Processing Importance
- Nonlinear Hierarchical Ordering Follows Multipath Structure
- Automatic Replicated Data Removal: Renormalization
- Hierarchically Processing of XML’s Duplicate and Shared Nodes
- Conclusion
Hierarchical Data Relationship Review
A review of hierarchical data modeling
relating relational and hierarchical data structures is presented first to
establish some background for what is to follow. Figure 1 below demonstrates a
common natural 1-to-M (one-to-many) data relationship. These are the most
common relationships and even have more significance and usefulness for
hierarchical structures. These relationships are shown in both hierarchical
format and relational rowset format. Notice that the hierarchical format has
not replicated data while the flat relational rowset has data replicated
because of the linear Cartesian product applied. In this case, the relational
replicated data is produced from the vertical parent-child effect.
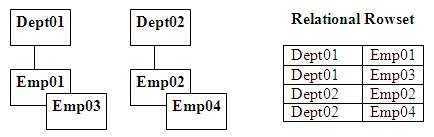
Figure 1: 1-to-M example
Figure 2 below demonstrates the less common M-to-1 data
relationship using the same data as in Figure 1. Notice in this example
compared to the previous 1-to-M example that the now inverted hierarchical
structure has produced Dept replicated data in the hierarchical data structure.
The ordering of the root data has also been performed for convenience; this may
or may not be desired. It carries no fixed semantic significance. Also notice
that the relational rowset is basically the same as the one in the previous
example except that data order has been reversed just to reflect the inversion.
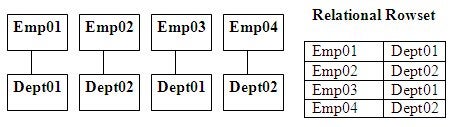
Figure 2: M-to-1 inversion example
Figure 3 below demonstrates a nonlinear multipath 1-to-M
hierarchical structure relationship. Notice in this multipath hierarchical
structure that the additional pathway of Proj which added a third column to the
relational structure produced more total data replications than expected from
its parent-child linear data replication addition. What has also been naturally
included in this result is the Cartesian product producing all the multipath hierarchical
unique data combinations occurring horizontally across the related pathways
when represented in the relational structure. These are the Emp/Proj
combinations related by Dept01 data occurrence and the Emp/Proj combinations
related by the Dept02 data occurrence. Also, notice in Figure 3 that the
multipath hierarchical data structure still did not produce any data
replications for its standard 1-to-M multipath hierarchical structure.
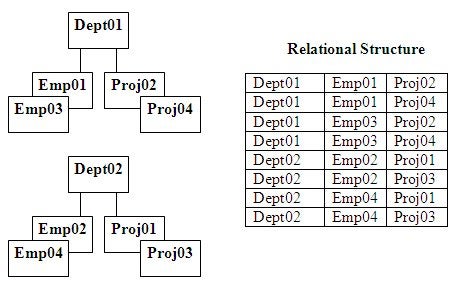
Figure 3: 1-to-M multipath example
Ordering Out of Hierarchical Order Causes Problems
Ordering flat data structures like relational data do not
present many rules and is straightforward. This is not the same for more
complex data such as hierarchical data. The problem of ordering out of
hierarchical order can be seen below in Figure 4. First, it can be seen that
the data replications for Dept have been introduced inadvertently, which can
produce incorrect results. Second, by ordering Emp before Dept naturally gives
it a higher significance level similar to the Dept/Emp inversion example in
Figure 2, which further supports the inadvertent inverted results in Figure 4.
Ordering should not affect the structure of hierarchical structures.
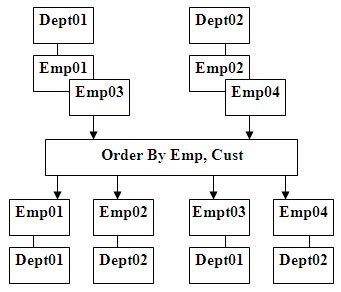
Figure 4: Ordering out of hierarchical order problem
Hierarchical Structure-Aware Processing Importance
It was shown in previous articles in this series that the
ANSI SQL LEFT Outer Join syntax can model multipath hierarchical structures,
and their associated semantics can support multipath hierarchical processing
when processed by SQL. Figure 6 has an example of this ANSI SQL LEFT Outer Join
data modeling syntax. The newer multiple use SQL ON clause used at each join
point replaced the single use WHERE clause for specifying join criteria. This makes
it more flexible and accurate eliminating ambiguity problems. The SQL-92 LEFT
Outer Join introduced the one sided join which preserves the left side of the
join when there is no data match. This LEFT Outer Join syntax supports the
basic hierarchical parent over child relationship, which models hierarchical structures.
Reversing the process of LEFT Join data modeling process
produces the ability to automatically extract the active hierarchical data
structure from the LEFT Outer Join string that models the hierarchical
structure being processed. This structure-aware processing is one of the most
important transparent capabilities necessary to automatically control many of
the automatic features covered previously. These include hierarchical
optimization, hierarchical output structure format, and SQL-to-hierarchical
operation mapping. Also included are capabilities that modify the structure: structure
joining; structure data modeling; and structure transformations. These
structure changes are also detected. The multipath features described in the following
sections relies heavily on structure-aware processing to support new nonlinear multipath
features.
Nonlinear Hierarchical Ordering Follows Multipath Structure
The ORDER-BY is one of those SQL operations that take on
special meaning when applied to multipath hierarchical structures and operations.
These operations are outside of SQL’s natural hierarchical processing. The value-added
hierarchical ordering solves this problem nonprocedurally retaining the ANSI
SQL syntax. As was shown above in Figure 4, ordering out of the hierarchical
structure presents problems when processing hierarchical structures. Flat
structures do not have these concerns since there is no structure and can be
ordered in any way. On the other hand, nonlinear data ordering in multipath hierarchical
structures introduces a new powerful capability shown in Figure 5 below.
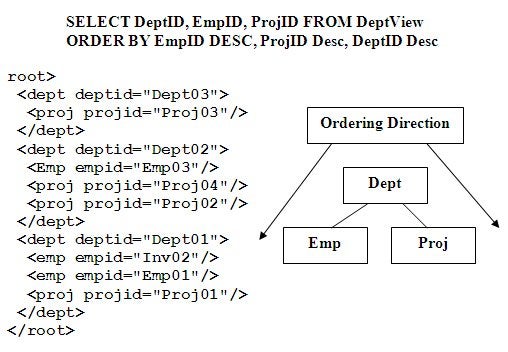
Figure 5: Nonlinear hierarchical ordering flow
Value added processing applied to SQL enables the ORDER BY
process to operate hierarchically as shown in Figure 5. The order that ORDER BY
arguments are entered, do not usually make any difference; they are automatically
processed to match the resulting hierarchical structure. Data values from the
same node are logically ordered in the same logical order they are specified.
The SQL ORDER BY example in Figure 5 with its three sort arguments will sort
them correctly even if they are on separate pathways. The two ordering
sequences Dept/Emp and Dept/Proj on separate pathways represented by Dept, Emp
and Proj on the ORDER BY statement are separately ordered correctly. This data ordering
is intuitive for hierarchical structures. This same multipath capability can be
applied to hierarchical summaries performed concurrently on multiple pathways.
Automatic Replicated Data Removal: Renormalization
The Cartesian product used by relational joins produce an
explosive amount of replicated data as shown in Figure 3. This replicated data
needs to be removed when the relational rowset is transformed back into a renormalized
hierarchical structure for processing. Otherwise, the results are not
hierarchically correct and can lead to invalid results. This is a difficult
operation and should be performed automatically if possible. This will assure
that it is performed transparently and accurately. To perform renormalization,
the data structure must be known. If the structure can be determined
automatically through structure-aware processing, the renormalization can be
performed automatically; otherwise, it must be coded by the user with the help
of user functions. The XQuery solution requires procedural user coding since it
does not have knowledge of the XML hierarchical structure of the data being
processed because of a number of its design limitations.
Duplicate data is different from replicated data described
directly above. Duplicate data is input data and represents data that is
significant. For this reason, it should not be automatically removed, but it
will complicate renormalization. This renormalization becomes further
complicated when there are no unique keys in the incoming data to help control
the data removal and the keeping of the required duplicate data. Having fewer prime
keys in the input data is possible with contiguous XML data, and the sequential
input data order may also require being preserved even in SQL processing. These
problems can be handled automatically by the adding of necessary information to
the input data.
Replicated data also occurs during data modeling, which can
also be triggered by structure transformations. For example, inverting a
typical 1-to-M structure such as Department over Employee where a department
can have many employees, to an M-to-1 structure of Employee over Department
where each employee now has its own department copy as in Figure 2. This
department copy is not significant for each employee. Re-inverting this M-to-1
structure back to a 1-to-M structure (Department over Employee) will
automatically renormalize (regroup) all the employee data back under their
single Department occurrence by automatically removing the replicated data. A
more complex renormalization is replicated data produced from the Cartesian
product produced from nonlinear multipath data as shown in Figure 3. This additional
level of automatic renormalization requires deeper analysis of the unnormalized
data cycles.
Hierarchically Processing of XML’s Duplicate and Shared Nodes
Some of XML’s unconventional features like duplicate named nodes
and shared nodes can be automatically tamed so that their inherent natural
network modeling capability can still be automatically processed
hierarchically. Duplicate named nodes and shared nodes are unconventional capabilities
for standard hierarchical processing. These capabilities and problems for
hierarchical processing are closely related.
Duplicate named node types are allowed in XML semistructured
data structures, but are not permitted in XML structured data structures. This
restriction actually allows structured data hierarchical structures to support
nonprocedural navigationless processing. The duplicate named nodes are used in
XML by XPath to take advantage of navigating automatically to the next closest
duplicate named node type. SQL usage does not make much sense of this for
nonprocedural use because the duplicate named nodes produce an ambiguous structure.
These duplicate named node types can be used in SQL by renaming them on input
so that each one has a different name. This is performed with SQL’s alias
feature shown as "AS" in the SQL query below in Figure 6. This will
keep the SQL query unambiguous with duplicate named nodes given their own
unique names. This will produce an unambiguous hierarchical structure shown
under Hierarchical Structure in Figure 6 below.
Sharing a node type using XML’s IDRef to make a new link path
usually causes network structures to be created in XML as shown in Figure 6
below where Emp-to-Addr is the IDRef link (indicated by a dashed path). SQL
nonprocedural hierarchical processing cannot handle network structures because
they are ambiguous with multiple paths to the same node and require procedural
navigation. ANSI SQL’s alias (rename) capability allows the IDref path to a
shared node to be renamed to another name than the shared node. This removes
the network ambiguity and restores the structure to a valid hierarchical form
while allowing the shared node to remain accessed as shown under Hierarchical
Structure in the in Figure 6 with a separate unambiguous path to the shared
node.
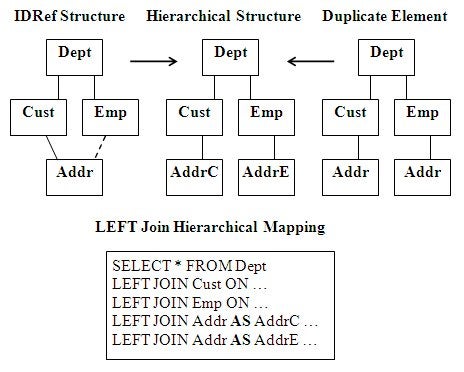
Figure 6: Hierarchical mapping solutions for network structures
Network structures unlike hierarchical structures can have
multiple paths to any given node making them ambiguous to query. Since SQL
hierarchical processing is a strict hierarchical process that maintains
hierarchical accuracy, it will not support network structures directly. However,
it provides a way to transparently map them to hierarchical structures using
the same SQL as shown in Figure 6 where the Hierarchical Structure can be
unambiguously accessed nonprocedurally. The same LEFT Outer Join alias solution
solves both IDref and duplicate named node problems by renaming both uses of
ADDR to different names. This allows hierarchical solid unambiguous principles
to remain intact.
Conclusion
This article has described a new level or change of natural
operation for hierarchical processing that becomes necessary and useful in a
multipath hierarchical processing environment. The SQL hierarchical examples
and capabilities shown and demonstrated in this article can be hierarchically
tested with XML using my company’s online interactive ANSI SQL Transparent XML
Hierarchical Processor Prototype at www.adatinc.com/demo.html.