


The two basic types of data structure transformation terms, Restructuring and Reshaping, are used interchangeably with data structure transformations. This article categorizes and defines these two types of data structure transformations and uses SQL to demonstrate the transformations, using SQL’s natural hierarchical data structure processing capability.
I have found that there are two basic types of data
structure transformations. I have also noticed that the transformation terms Restructuring
and Reshaping are used interchangeably with data structure transformations.
These two terms bring to mind different types of transformations I have associated
with the two basic transformations. In this article, I will categorize and
define these two types of data structure transformations. I will be using SQL
to demonstrate these types of data structure transformations using SQL’s
natural hierarchical data structure processing capability.
Data structures are built to a great extent by utilizing the
related data values in the data to make the linkages that can bring the data
together in different ways. Restructuring is performed by using these data relationships
in the data as linkages in order to change the structure to model these new
relationships. This is done by taking the structure apart as needed and applying
new data relationships not currently used or reusing them differently. This
introduces new meaning and semantics to the resulting structure. In addition,
these data relationships can involve comparisons and formulations to make the
new relationships linkages.
Changing the topic of Restructuring to Reshaping, reshaping
brings to mind a molding process by shifting pieces of the structure around as
in molding a piece of clay. This means that that there are no limitations to what
the resulting structure can be, allowing any structure to be transformed into
any other structure producing any-to-any structure transformations. The trick
with performing this type of transform is that the semantics of the structure
must drive how the transform is performed in order to preserve the basic semantics
that are applied to the creation of the new structure. This means the naturally
implied data relationships from the physically or logically juxtaposition of
the data in the structure flows with the structure as it is molded. This
produces the desired new structure while taking into consideration the current
semantics represented by the data.
Restructuring is used when new semantics are needed and data
relationships are available to support this. The resulting structure is not a
concern. Reshaping is used when a specific result structure is necessary as in
hierarchical data modeling. The resulting semantics are not a primary concern
but are expected to be hierarchically derived from the source structure.
Restructuring requires that the necessary data relationships are available
while Reshaping does not require any external or internal requirements so it is
always available to use.
Restructuring Example
The following SQL Restructure operation in Figure 1 slices
out the Invoice node shown below, and makes it the new root in the resulting
structure. The data relationship used in making this new structure may be the
same or a previously unused data relationship. If this data structure was
retrieved from a contiguous data structure like XML there may not have been any
physical data relationships to use. But on the other hand, once any type of
data structure (physical or logical, contiguous or linked) is retrieved into a
relational rowset it can be freely taken apart. Reassembling will depend on the
data relationships that can be made.
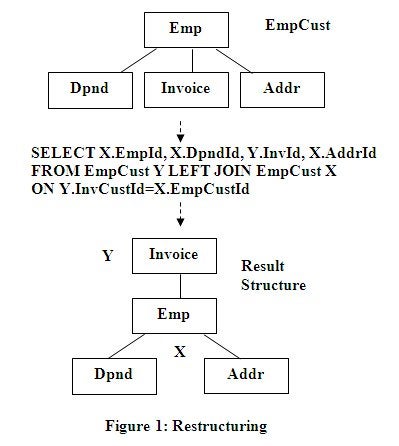
The Alias feature of SQL beside its renaming use allows
making multiple, separately named copies of a structure in the rowset, which can
be used in taking apart the structure above and hierarchically reassembling it.
The separately identified data from the two named copies of the identified structure
in the FROM statement above is identified by the prefixes of X and Y associated
with their created data copies in the FROM clause. The LEFT Outer join in
Figure 1 models the restructured data as Y over X since Y is preserved when X
is not. This is why InvID is identified in the SELECT statement with a Y prefix
and EmpID, DndID and AddrID are identified with an X prefix in the SELECT
statement since InvID is desired at a higher hierarchical level than the others.
The higher level Y.InvID is used in the SELECT List and is used in the ON
clause to reflect its proper position in the new hierarchy.
Restructuring Example Additional Level
This is the same as the previous Restructuring example
except in addition to moving the Invoice to the top of the new structure, the
Addr node is repositioned under the Dpnd node. This is done by adding another
level to the structure by using another LEFT Join to attach the Addr node under
the Dpnd node.
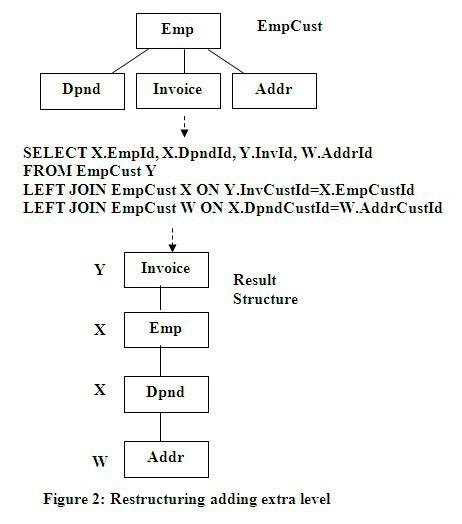
Notice
in the above SQL in Figure 2 compared to the previous SQL in Figure 1 that the
additionally added LEFT Join creates another copy of the structure to reference
using the prefix of W. The AddrId field in the SELECT list now uses the W
prefix so it can be referenced in the new LEFT join. This LEFT join is used to
move the Addr node under the Dpnd node.
Reshaping
The following examples will demonstrate a number of data structure
reshaping examples that cover linear to linear, linear to nonlinear, nonlinear
to linear and nonlinear to nonlinear structure transforms. The previous
restructuring used physical data relationships in the data to perform the
transform. This can not be used in reshaping and a technique similar to the
restructuring is used. It uses the same processing of using multiple copies of
the structure, but the coordination between the copies of the structures is
different in that the relationship of the structures is now made between the same
named node types of the two structure copies that are being moved in the order
that they are being moved.
Inverting a 1 to M Linear Three Level Structure
This is a linear structure inversion using nodes Cust over
Emp over Dpnd (a series of 1 to M relationships) in Figure 3 below. This will
demonstrate that the alignment joining starts at the bottom of the structures,
and drives the inversion upward at each node as the selected inverted node (in
bold) from each level is selected: SELECT first: X.Dpnd, second: Y.Emp, third:
Z.Dpnd. Only these three nodes represented by their data are selected once each
for output so they are squeezed together through natural node promotion to keep
their structure which is naturally inverted and now has M to 1 relationships.
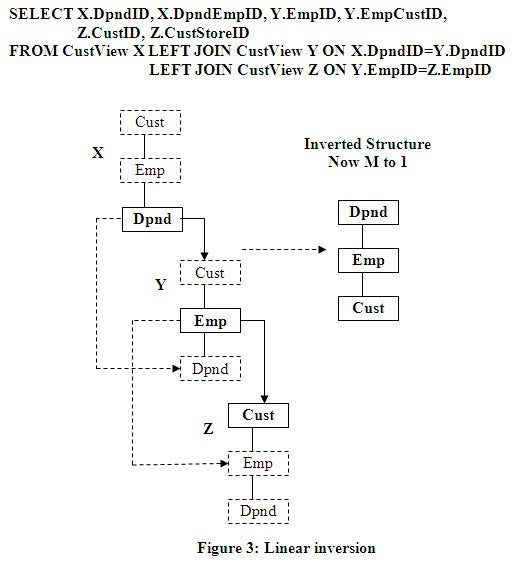
Linear to Nonlinear Reshaping Logic
Linear structures can be reshaped into nonlinear structures.
In this example in Figure 4 below, the linear structure Cust over Emp over Dpnd
can be used to generate the structure Emp directly over the siblings Dpnd and
Cust. Two copies of the input structure are necessary and are joined by their
common Emp node since it is the starting node to building the new structure.
Only two copies of the structure are necessary because the first copy can be
used to move two nodes, Emp over Dpnd, which are already related as required.
This places Emp over the Dpnd and Cust siblings because Emp is linked to Cust.
This creates the nonlinear structure desired and these same node values (in the
SELECT list) will be selected to create the nonlinear structure desired. By
placing Emp over Cust, Cust is naturally and correctly replicated.
The previous linear examples and this nonlinear example have
not lost the semantics of the input structure in the new structure because the
semantics have been kept the same or inverted. This means the nodes have
basically kept attached to the same nodes as shown below in the derived result
structure. Emp over Dpnd remains the same while Emp over Cust has been
inverted.
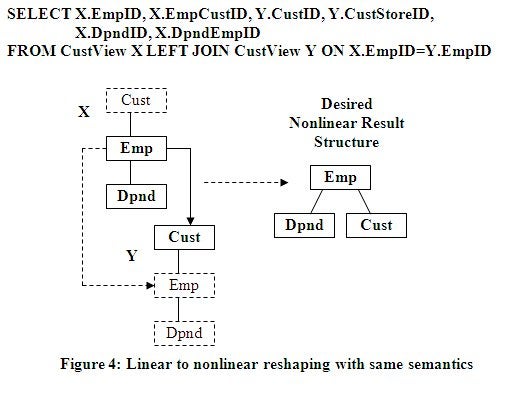
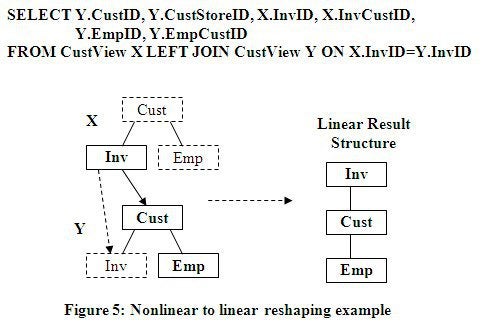
Nonlinear to Linear Reshaping
Nonlinear structures as input can also be used to build
linear and nonlinear structures. In fact, nonlinear structures offer more
flexibility in how they are utilized because their multiple paths offer more
opportunity to find the correct reshaping being sought. This means less input
copies need to be used.
The nonlinear input structure in Figure 5 below can be
duplicated to create a linear structure reshaping of itself using the SQL below.
Since we are starting with the Inv node as the root, this will be the first
matching link. Cust becomes available in the second level structure, which is
valid since it is related to Inv the related link point. Emp can also be
selected from the same lower structure copy since it is already located under the
Cust node.
Nonlinear to Nonlinear Reshaping
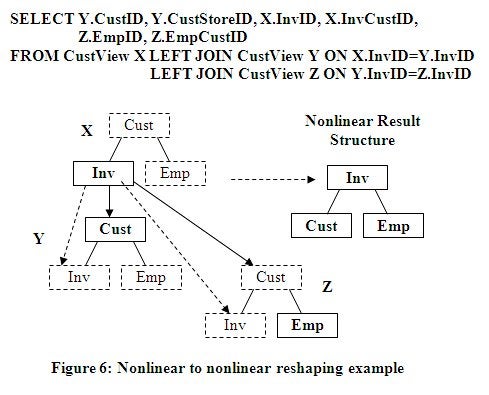
This nonlinear to nonlinear example, in figure 6 below, is
very similar to the previous nonlinear to linear SQL example in Figure 5, where
the linear structure Inv over Cust over Emp was produced easily. The current
example below demonstrates that a nonlinear structure can transform into a
different nonlinear structure. This example copies the previous example but
places Emp not under Cust but under Inv making Cust and Emp siblings for this
structure. This requires a third copy of the input structure also matched to
Inv because that is where Emp is being attached to. The Emp node is accessed
indirectly from Inv up to Cust then back down to Emp, a powerful related
semantic reshape. Basically, the third structure and additional join in this
example was necessary to move Emp from under Cust to under the Inv node.
Polymorphic Reshaping
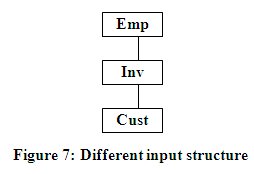
A polymorphic reshaping does not rely on the structure of
the input structure. This means that the input structure could be in any shape.
The reshaping capability shown in Figure 3 and 6 do support polymorphic
reshaping because only one node is moved per join. This means any shape
structure with the same nodes can be transformed into the desired resulting
structure. For example, the different input structure in Figure 7 would produce
the same results from the SQL in Figure 6. The examples in Figure 4 and 5 are
not polymorphic because it relies on a specific shape of the input structure by
moving two related nodes at one time. The choice of using reduced steps or a polymorphic
solution is up to the user. The examples in Figures 4 and 5 could have been
written to be performed in three steps moving a single node at a time making
them polymorphic when it is useful.
Conclusion
The SQL Reshaping and Restructuring shown do take a little
bit of procedural programming. But a high level nonprocedural transform
language could be designed for reshaping based only on the desired structure
and the SQL can be generated or internally performed.
It may have occurred to you that the need to create multiple
copies of the structure in the examples, which could be costly in memory use. Most
SQL processors optimize the multiple copies of the structure to use one
physical copy.
The different operations of Reshaping and Restructuring can
be combined as needed. The transformation examples shown are described in more
detail and can be tested at http://www.adatinc.com/demo.