


Data structure virtualization is the constructing of a data structure utilizing pieces or fragments from other data structures. This article demonstrates how Data structure virtualization can be done in ANSI SQL utilizing hierarchical processing techniques to produce hierarchically structured virtualized output.
A recent article in this series of articles on ANSI SQL Hierarchical
Processing described hierarchical
data structure transformation in SQL. Data structuring transformation is
the converting of a data structure into a different structure while retaining the
original data unless it is not desired in the resulting structure. Data
structure virtualization is the constructing of a data structure utilizing
pieces or fragments from other data structures. This article will demonstrate
how this can be done in ANSI SQL utilizing some of the hierarchical processing
techniques covered in previous articles in this series used to produce
hierarchically structured virtualized output.
Basic Hierarchical Structure Defining and Joining Review
In Figure 1 below, two structures are hierarchically
combined using the Select statement shown. The basic structure definitions of
views ABC and XYZ are modeled hierarchically using the hierarchically oriented
LEFT Outer join operation, which preserves the left argument and not the right
argument when there is no match found. In addition, the outer join uses the newer
more specific ON clause at each join point to specify the node link points
using join criteria. This can be seen in the ABC and XYZ view structures
defined below. These two hierarchical structured views can also be joined using
the LEFT Outer join operation as shown below. Normally the link point to the
lower level structure is the root node as shown. The expanded ABC and XYZ views
produce the internal LEFT Outer Join combined structure automatically. This
combined view models the hierarchical structure shown below, which is processed
by the SQL processor where the associated LEFT Outer Join semantics controls
its hierarchical operation.

A Valid Semantics for Linking Below Root Review
In a previous article in this series, linking
below the root was covered. This gives unlimited control of linking
structures together. Using the query shown in Figure 2 below, the upper level
structure is attached to the lower level structure at a node below the root
node to the Z node. The data link points between the structures being combined
are used to match up data relationships between the structures being combined. Linking
below the lower level structure root node level requires that the lower level
structure to be fully expanded before it can be joined to the upper level
structure. This occurs automatically and can be seen in the combined view above
in Figure 1. Because of the natural hierarchical nesting occurring in the
expanded LEFT Outer Join, the two constructed structures have been kept
separate. This is controlled by the final ON clause, which now performs the joining
of the two fully expanded view structures, ABC over XYZ. This is actually a
data filtering operation applied to the lower structure’s link point (node Z in
this case) and will filter the entire lower structure in isolation hierarchically
from the link point outward in all path directions.
Because the lower level structure has its hierarchical
structure established before the linking process it can be treated as a single
fixed entity regardless of where it is linked or whether it is a logical or
physical structure. Since node Z is already affected and controlled by other
nodes above it (node X in this case), the hierarchical data modeling link point
is always the root node of the lower structure. This is shown in the Modeled
Structure of Figure 2 below while the data relationship data filtering occurs
between nodes C and Z. This consistently preserves the data semantics of the
structures involved and the hierarchically combined structure.
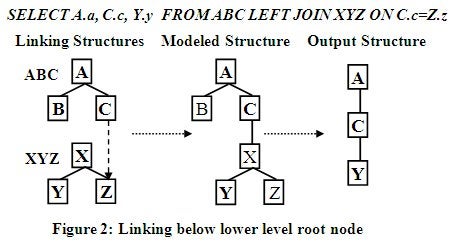
Also demonstrated in the example in Figure 2 is the powerful
variable SQL SELECT list, which dynamically controls the range of processing
necessary by specifying the specific data to be output. In this case it is data
from nodes A, C and Y. Notice that node X on the pathway to selected node Y was
not selected and this was automatically closed up by Node Promotion before
output. This is a standard hierarchical operation. This node promotion
operation also maps directly to the relational SELECT projection operation.
This produces a nice natural hierarchically condensed result.
Extracting and Manipulating Multiple Fragments Review
The previous examples in this article only extracted a
single data segment per data structure to contribute to the result structure
being constructed from multiple structures. From a previous article in this
series, the query in Figure 3 below demonstrates the technique for deriving and
separately manipulating multiple fragments from a single structure to perform a
data structure restructuring. It separates the original structure into two
structures. One consisting of the Invoice node and the other consisting of the
original structure minus the Invoice node and recombines them placing the
Invoice node on top using an existing data relationship.
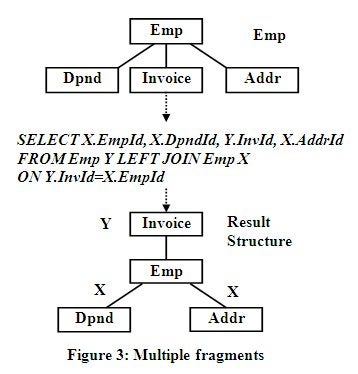
The Alias feature of SQL enables renaming a view or data
structure so it can be separately identified by different names. This feature can
be used to take apart a structure into multiple fragments and hierarchically
reassembling them by manipulating each fragment separately. The separately
identified fragments from the identified structure in the FROM statement above are
identified by their correlation names of X and Y, which is used as a qualifier
on data names. The LEFT Outer join in Figure 3 models the restructured data as
Y over X since Y data is preserved when X data is not. This is why InvID is
identified in the SELECT statement with a Y qualifier while EmpID, DndID and
AddrID are identified with an X qualifier in the SELECT statement. This is
because InvID is desired at a higher hierarchical level than the others. The
higher level Y.InvID is used in the SELECT List and in the ON clause to reflect
its proper position in the new hierarchy.
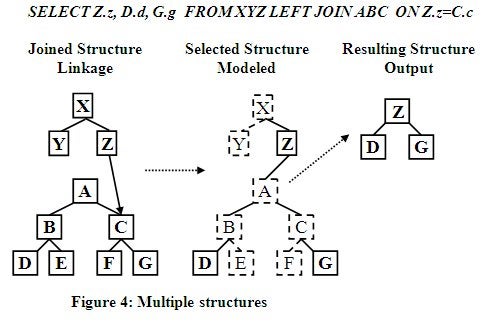
Virtualization Composed of Multiple Structures
For the following examples, the ABC view has been extended
as shown below in Figure 4. In this example two structures are combined utilizing
the LEFT Outer Join to hierarchically link below the lower level root in the
query. This allows any-to any node linking between the structures. Only the
desired data in the SELECT clause is output triggering node promotion. This
aggregates the data nicely into a single condensed structure where nodes D and
G are brought up and directly under node Z. This process is indicated below in
Figure 4 where the left diagram shows how the structures are related. The
middle diagram shows the modeled structure, the inactive pathways have dashed
lines and unselected nodes have dashed boxes. The example on the right is the
result structure. Also notice that node B was on an active path even though it
was not selected for output. The path is active because it is needed to
navigate to referenced node D.
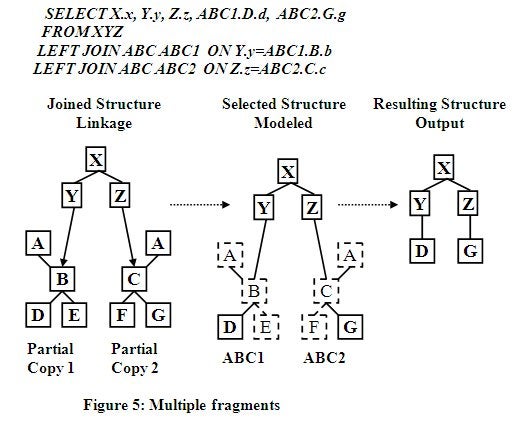
Virtualization Manipulating Separate Structure Fragments
The query and example below in Figure 5 uses the same basic
capabilities as the previous example, but in this example separate fragments of
the lower structure ABC are separately moved to different locations under the
XYZ structure. In this case, node D is placed under node Y while node G is
placed under node Z. This is achieved by using the SQL Alias feature to enabled
separate references to the ABC view structure using either ABC1 or ABC2 to qualify
the different view references and their associated data parameters on the
SELECT clause. This is indicated below with the two data fragments qualified using
ABC1 and ABC2. Notice that each fragment is positioned separately by its own
hierarchical LEFT Outer Join statement.
Association Table Usage
The previous data virtualization examples all relied on the
use of existing data relationships in the data to recombine the data fragments.
Without data relationships to use there is a problem for recombining the data
fragments. An externally maintained relational association table of physically related
sets of keys in rows can be used to make this association where there was no
previous data relationships to use. This is shown below in Figure 6 using the
association table shown.
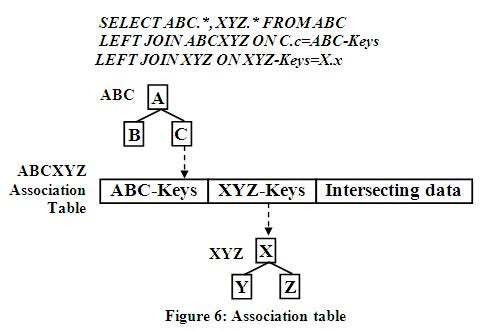
The above SQL query in Figure 6 does not select any data
from the association table making the association table operation seamless and
transparent placing node C directly over node X in the output structure. These
association tables can easily support many-to-many relationships which are modeled
as one-to-many relationships when operating hierarchically in a top to bottom direction.
The association table usage can also be easily reversed by swapping the
association table key usage around. This places structure XYZ over structure
ABC. This also produces a one-to many relationship and structure. Many-to-many
relationships like Part and Supplier can contain intersecting data like Price
for each Part and Supplier combination, which can be easily selected for output
and automatically placed in a intersecting data node between nodes C and X by
selecting Price for output.
Conclusion
Data virtualization is the ability to control, isolate and
combine fragments from multiple data structures into a single meaningful structure.
The data virtualization of data structures shown in this article utilized the
capabilities used in hierarchically joining structures below their lower level
root, selecting only the data desired for output, and the node promotion
resulting from the eliminated nodes of the structures. The technique for
isolating multiple segments and their separate manipulation was also demonstrated.
The SQL hierarchical examples and capabilities shown and
demonstrated in this article can be hierarchically tested with XML using my
company’s online interactive ANSI SQL Transparent XML Hierarchical Processor
Prototype at www.adatinc.com/demo.html.
»
See All Articles by Columnist
Michael M. David