


Learn how hierarchical data processing can be optimally driven automatically by its hierarchical structure semantics. When applied to SQL hierarchical data processing, this structured semantics offers optimization beyond current relational processing. In addition, this hierarchical optimization works with SQL dynamic processing and offers new relational capabilities.
My previous Database Journal article covered the ANSI SQL Hierarchical Data
Processing Basics. This hierarchical data
processing article will show how hierarchical processing can be optimally
driven automatically by its hierarchical structure semantics. When applied to
SQL hierarchical data processing, this structured semantics offers optimization
beyond current relational processing. In addition, this hierarchical
optimization works with SQL dynamic processing and offers new relational capabilities
that will be covered in this article.
Hierarchical Structures and Processing
The Left Join operation preserves its left argument and not its
right argument for unmatched joins. This causes it to operate hierarchically
allowing the left parent to exist even with no matching right child argument,
but the reverse is not possible; children cannot exist without their parent. As
explained in the previous hierarchical structure processing basic articles, the hierarchical
structure in Figure 1, where tables are represented as hierarchical nodes, can
be defined hierarchically by a series of LEFT Outer Joins. These LEFT Joins
model hierarchical structures using their hierarchical syntax to model the
structure and specify its associated hierarchical semantics, which defines its parent/child
data preservation semantics. This allows hierarchical views’ data modeling
syntax and associated semantics to be supplied directly to the relational
engine when its view is processed at query invocation. This automatically turns
your ANSI SQL processor into a powerful full hierarchical processor.
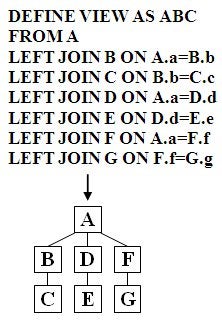
Figure 1: Global Structure
Notice in the hierarchical view definition above in Figure 1
the use of the newer outer join ON clause to separately specify the link points
between hierarchical pairs of nodes. This offers an exact and unambiguous
hierarchical mapping that can support multiple paths. The ANSI SQL LEFT Outer Join
hierarchical structure definition doubles as structure metadata to specify how
the data is hierarchically processed. This is possible because hierarchical data
structure processing must follow hierarchical data preservation principles inherent
in the data structure. These LEFT Outer Join definitions of hierarchical
structures can be automatically generated from the information in hierarchical metadata
sources such as XML schemas or even IBM’s IMS and VSAM database definitions.
This is also useful because all forms of hierarchical structures, contiguous or
linked and physical or logical structures, have the same hierarchical
processing principles and can be seamlessly processed heterogeneously with standard
hierarchical processing. All that is necessary are the addition of specific
access modules. These access modules will be different from similar access
modules used today because they will be preserving the semantics of the
hierarchical structures on retrieval because the data will be processed
hierarchically.
Hierarchical Optimization
Because of a hierarchical structure’s natural data
preservation, a very powerful optimization can be easily applied at query invocation.
This optimization is based on the data referenced in nodes and specifies that
only the referenced nodes at query execution and any nodes on the path to
referenced nodes are necessary for processing. All other nodes can be
eliminated entirely from processing. It is obvious that referenced nodes are
required. The reason that unreferenced nodes on the path to referenced nodes
are needed is that the paths to referenced nodes are needed to preserve the
semantics of the access path to reach the desired data. The data structure below
in Figure 2 is optimized based on the query shown referencing only nodes A, C
and F.
The arrows in Figure 2 indicate LEFT Outer Joins for
specific nodes that can be removed or ignored for the active query shown without
changing the semantics or results of the query. This optimization does preserve
the semantics of the query, but also has a beneficial side effect that can
reduce unneeded data replications caused by joins with unneeded tables or
nodes. This can actually help reduce problems caused by these additional
extraneous data replications. Hierarchical structures designed specifically for
hierarchical data processing always remove all data replications. It is helpful
to know that replicated data are extraneous while duplicate data are valid and meaningful.
They should be processed differently.
As shown above in Figure 1, the newer more flexible ON
clause replaces the single WHERE clause by using an ON clause at every join operation.
This causes a reference to every node, but this is not taken into consideration
for this optimization because it is a self-reference and if nodes are not
necessary, their self-reference is removed, as is the unneeded node. This is
supported by hierarchical processing’s hierarchical data preservation. This demonstrates,
in Figure 2, how easily the LEFT Outer Join hierarchical view can remove
unneeded nodes for the dynamic rebuilding of the run time query.
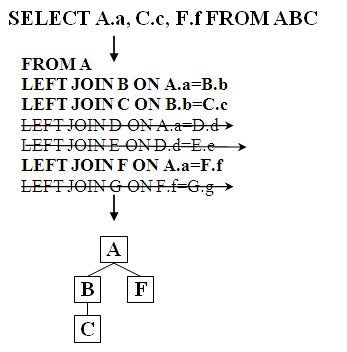
Figure 2: Optimized Access
The hierarchical optimization, in Figure 2 above, would not
normally be recognized by standard relational processing, which has no idea it
is operating hierarchically. As previously mentioned, hierarchical optimization
can be performed immediately when the query is invoked at run time. This is an
extremely powerful semantic optimization, but does not replace standard
relational optimization, which will be performed naturally after the
hierarchical optimization is performed. This previously performed hierarchical
optimization can have a further positive effect on the following standard
relational optimization. It can enable standard relational optimization to
perform more effectively by simplifying the run time query in ways it could not
detect making relational optimizations more clear and detectable.
Optimization Enables Global Views
A significant benefit of hierarchical optimization is that it
enables global hierarchical views to be used without any additional overhead. Normally
views that have unnecessary tables at execution cause a great deal of overhead.
The previous solution for this has been for the user to code many sub views,
each tailored specifically to the required result. Besides having to create many
different sub views for the same data structure and constantly adding views,
this is also difficult for the user to be aware of all the different views.
Hierarchical optimization allows global views with all nodes specified so that
it can be dynamically capable of processing any number of different sub views
without overhead. This is because each query is dynamically optimized to match
the needs of the active query. The query above in Figure 2 is an example of a
global view being automatically utilized.
Schema-free Processing Enabled by Global Views
Another benefit of hierarchical optimization is that it also
enables schema-free processing supported naturally by SQL navigationless processing,
which was covered in my previous article. Schema-free processing allows queries
to be specified without user navigation when used for XML data. This also means
the user does not need to know the data structure and this enables non-technical
users to access XML data. Since users do not need to know the structure for
these powerful schema-free queries or where the data is located in the
structure, they need to be free to specify data anywhere in the structure and
this requires a global view. The query in Figure 2 above is also an example of
a schema-free query allowing its use without the user’s need to navigate or
know the data structure.
SELECT List Controls Processing Dynamically
It is important to point out that the SQL SELECT clause and
its variable SELECT list supports full dynamic processing. This dynamically controls
optimization, global views, and schema-free processing. The SELECT list
dynamically specifies the output data and this directly affects the processing
that is required. Since SQL is nonprocedural, there is no user coding
necessarily for processing. In this case, the processing is established
dynamically and is optimized only to cover the required results, which are
inferred by the current dynamically specified output. In other words, the variable
SELECT list dynamically controls the required processing as shown in the
optimized easily rewritten Left Outer Join string in Figure 3 below. It limits
the internal processing for the query and you can notice that it does not
contain any processing for nodes D, E and G.
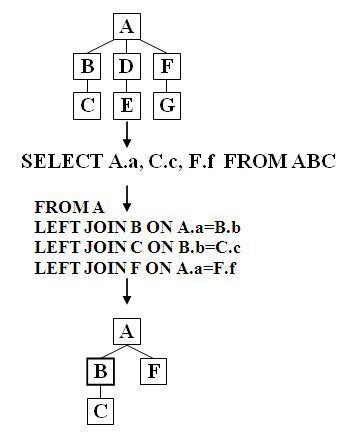
Figure 3: Optimized Processing
SELECT List More Powerful Than Realized
This dynamic optimized processing may not seem that
impressive because with SQL it is easily applied automatically, but when
compared to XQuery it will become clear how much more automatic and powerful SQL
is. The processing of the SQL query above in Figure 3 is truly nonprocedural. This
process is inferred from the hierarchical data structure defined in the LEFT
Outer Join view and its natural processing principles. It is dynamically controlled
from query to query by the variable SELECT list. Most books on XQuery mention
that it contains the three key processing elements of SQL. These are SELECT,
FROM and WHERE. XQuery has a WHERE clause data filter and has something similar
to the FROM clause, but it does not have anything that approaches the variable
and automatic power of SQL’s dynamically variable SELECT list.
SQL’s powerful variable SELECT list with its dynamic
processing capability is not found in XQuery. XQuery through the use of its FOR
syntax requires the user to set up the proper hierarchical nesting looping
structure to match the desired hierarchical processing required. The data items
required to generate the output values must be placed accurately at their correct
nested looping levels. This is procedural coding and is not performed
automatically or nonprocedurally. Any changes to the query represented in this fixed
code must be procedurally adjusted and tested by the user. In SQL, this could
be achieved simply by altering the SELECT list. This is real nonprocedural and
declarative power.
Conclusion
An important test for proper query optimization is that it
does not negatively affect the result or its external operation. Interestingly,
the powerful hierarchical optimization described in this article also introduced
two beneficial side effects. These were the reduction of superfluous relational
data replication and then there was the automatic creation of the global view
and the further capabilities it enabled. These were all seamless beneficial additions
and stayed within the tenets of proper optimization.
Additional Resources
Creating Hierarchical Data Structure Mashups