International companies with offices and customers around
the globe often face a problem. Data specific to a location is updated at that
location, but the updated data still need to be available to other locations.
Take an international sales website for example. Customers from different
countries go to a landing page, select the login links written in their native
languages, and are redirected to the login pages for their countries. Behind
the scene, a customer is actually directed to the application server hosting
the login page that he/she selects. In this scenario, the site traffic for the
international sales company is distributed across application servers. As you
know, the application servers need a database backend to store customer and
order information. Therefore, the database workload also needs to be
distributed among database servers. Peer-to-Peer replication provides a very
suitable solution for this kind of scenario. First of all, the data is
partitioned naturally by country. Therefore, data records specific to a country
is only updated at the data servers residing at that country. Although conflict
detection is introduced in Peer-to-Peer replication in SQL Server 2008, the
conflict resolution is simply based on the peer ID. If a row identified by the
primary key value is inserted, updated, and/or deleted at more than one node,
the Distribution Agent will fail to deliver commands and remain in a stalled
state until the conflict is resolved manually. You will see an example in this
article series. Second, Peer-to-Peer replication builds on the foundation of
transactional replication, and can be viewed as a multiple-node transactional
replication with each node published to other nodes, and at the same time, subscribed
to other nodes. Therefore, writes on one server are propagated to other servers
in near real-time, thus making data changes available to other locations
quickly. Peer-to-Peer replication also provides data redundancy and read
scalability as each server has a copy of the replicated data.
In this first installment of the article series, we will
describe the steps to configure a two-node Peer-to-Peer replication topology.
In our example, we create a database called GlobalSales, and
in this database, we create a Customers table, which stores customer contact
information, such as customer ID, first name, last name, country code, creation
date. Here is the script to create the database and table.
CREATE DATABASE GlobalSales
GOUSE GlobalSales
CREATE TABLE Customers
(ID nvarchar(10) CONSTRAINT [PK_Customers] PRIMARY KEY,
FirstName nvarchar(100) NOT NULL,
LastName nvarchar(100) NOT NULL,
CountryCode nvarchar(3) NOT NULL,
CreationDate datetimeoffset CONSTRAINT [DF_Customers_CreationDate] DEFAULT GETDATE()
)
GO
Note that the Unicode data type, nvarchar, and the new date
and time type with time zone awareness, datetimeoffset, are used to provide
international support.
Assume that we have two servers, POWERPC in the US and
DEMOPC in China. We will use SQL Server Management Studio (SSMS) to configure
two-node Peer-to-Peer replication topology between them. You can also write
T-SQL scripts to configure the replication. However, it is more error-prone and
less straightforward. The recommended way is to use wizards in SSMS to
configure the topology and also generate the scripts. Save the scripts in case
you need to recover the configuration later or use the scripts as templates to
configure other servers.
1. Configure distribution for each node
First, make sure the SQL Server Agent service is running on
each node. Otherwise, you will receive a misleading error message as shown
below.
2009-03-27 11:49:51.68 spid53 SQL Server blocked access to procedure 'dbo.sp_set_sqlagent_properties' of component 'Agent XPs' because this component is turned off as part of the security configuration for this server. A system administrator can enable the use of 'Agent XPs' by using sp_configure. For more information about enabling 'Agent XPs', see "Surface Area Configuration" in SQL Server Books Online.
This actually implies the SQL Server Agent is not running
because when the SQL Server Agent service is started, it automatically enables
the “Agent XPs” option, and when it’s stopped, it automatically disables the
“Agent XPs” option. You don’t need to run sp_configure to enable the option.
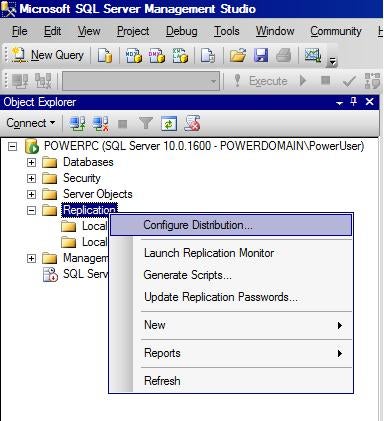
Next, right-click the Replication folder, and then
click Configure Distribution to invoke the Configuration Distribution
Wizard.
You can just follow the instructions in the wizard to
complete the configuration. Here are a few things to point out.
- We will let each node act as its own Distributor and use its own distribution
database. This eliminates the potential of having a single point of failure. If
you use a remote Distributor, do not use the same remote Distributor for all
nodes.
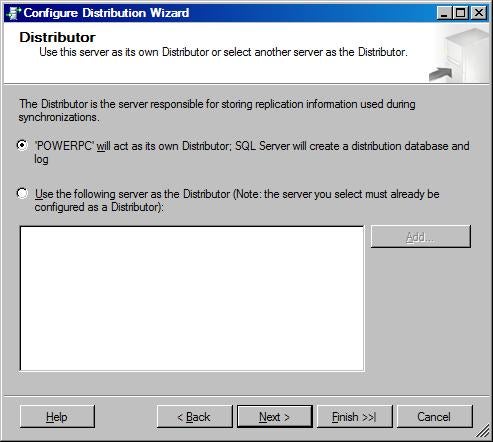
- Although the snapshot folder is not used by peer-to-peer
replication at the other nodes, it is still required to configure a Distributor.
You can just use a local folder for it.
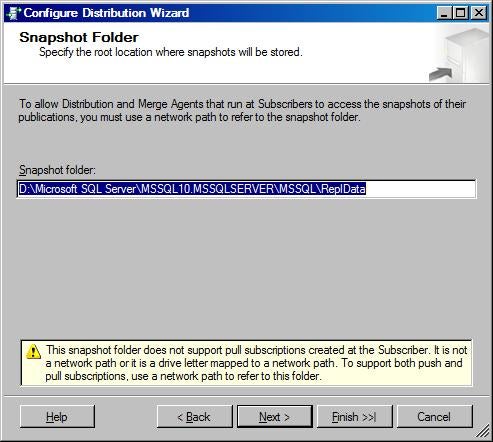
- Let the wizard generate a script file. The script file can be
modified later to configure another node or recover the replication
configuration from a loss of the databases involved in the replication or
server damage.
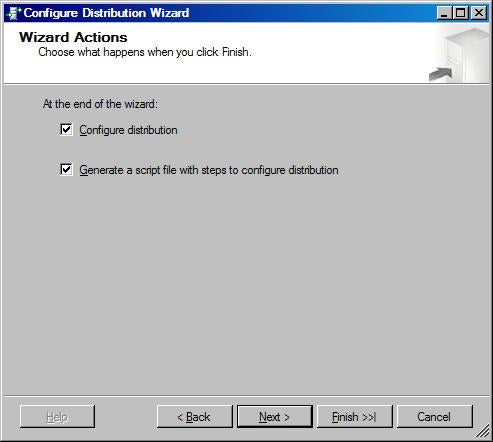
At this point, these maintenance jobs for
replication have been created.
Agent history clean up: distribution
Distribution clean up: distribution
Reinitialize subscriptions having data validation failures
Replication agents checkup
Replication monitoring refresher for distribution.
2. Create a publication at the first node. In our example,
create a publication called PubSales for the Customers table in the GlobalSales
database on POWERPC.
First, right-click the Local Publications folder
under the Replication folder. Select New Publication to invoke
the New Publication Wizard.
You can just follow the instructions in the wizard and go
through the configuration process. Here are a few things to point out.
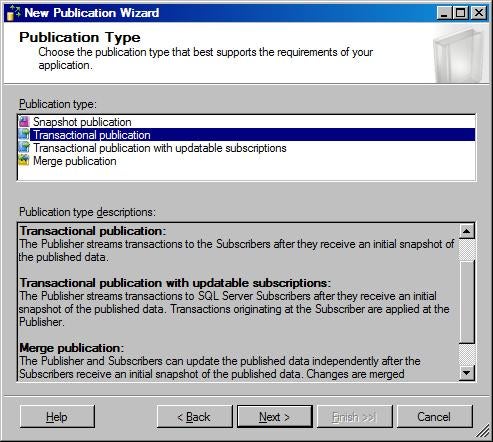
- On the Publication Type page, select Transactional
publication. As discussed, Peer-to-Peer replication builds on the
foundation of transactional replication, and can be viewed as a multiple-node
transactional replication.
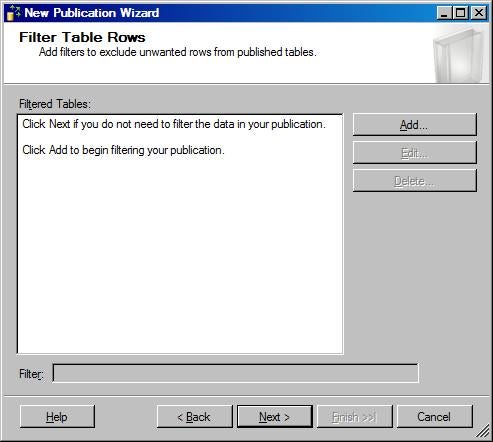
- Filters cannot be defined on the Filter Table Rows page,
because row and column filtering are not supported in peer-to-peer replication.
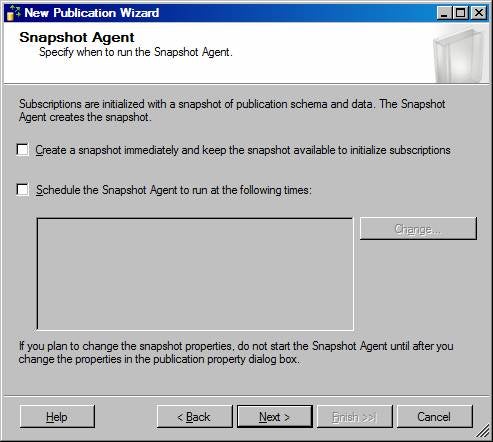
- As snapshot is not being used to initialize schema and data in
Peer-to-Peer replication, on the Snapshot Agent page, clear both “Create a
snapshot immediately…” and “Schedule the Snapshot Agent to run at the following
times”.
After this, a log reader agent for the GlobalSales
database is created.
POWERPC-GlobalSales-1
3. Enable the publication for peer-to-peer replication.
Right-click the PubSales publication, and click Properties.
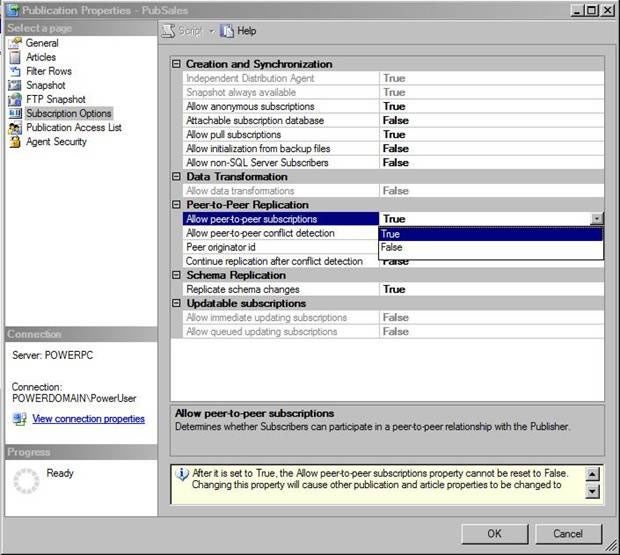
On the Subscription Options page, enable the property
Allow peer-to-peer subscriptions. Please note that the Allow
peer-to-peer conflict detection option is enabled by default although it is
not shown in the figure.
4. Before configuring the two-node replication topology, we
need to initialize the schema and data at the second node DEMOPC.
You can create a SSIS package or write T-SQL scripts to copy
the schema and data to DEMOPC. However, the easiest way is to back up the GlobalSales
database on POWERPC and restore the backup to DEMOPC. Please note that the
backup must be taken after the publication at the first node POWERPC is created
and enabled for peer-to-peer replication because at that point, the log reader
on POWERPC is already running. Even if activities occur on POWERPC before the
topology is completely set up, the log reader agent on POWERPC will copy the
new transactions from the transaction log into the distribution database, and
the distribution agent will apply the transactions to DEMOPC after the topology
is set up.
— Back up GlobalSales database on POWERPC
BACKUP DATABASE GlobalSales
TO DISK=’ D:\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\Backup\GlobalSales.bak’— On POWERPC, insert a row into the Customers table to test if
the row will be created later on DEMOPC after the topology is set up.
INSERT INTO Customers (ID, FirstName, LastName, CountryCode)
VALUES (‘USA-0001’, ‘Melissa’, ‘Clinton’, ‘USA’)— Restore the backup on DEMOPC
RESTORE DATABASE GlobalSales
FROM DISK=’\\POWERPC\D$\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\Backup\GlobalSales.bak’
WITH MOVE ‘GlobalSales’ TO ‘D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\GlobalSales.mdf’,
MOVE ‘GlobalSales_log’ TO ‘D:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\GlobalSales_log.LDF’
Note that at this time, the Customers table on POWERPC has
one row, but the Customers table on DEMOPC is empty.
5. Configure the two-node replication topology.
First, right-click the PubSales publication on POWERPC, and
click Configure Peer-to-Peer Topology to invoke the Configure
Peer-To-Peer Topology Wizard.
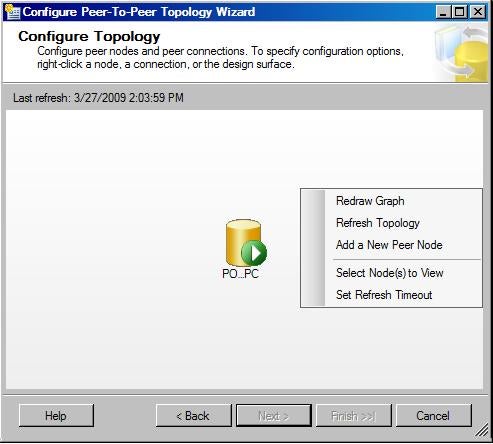
On the Publication page, select the PubSales
publication. Click Next. On the Configure Topology page,
right-click the design surface of the page, and then select Add a New Peer
Node.
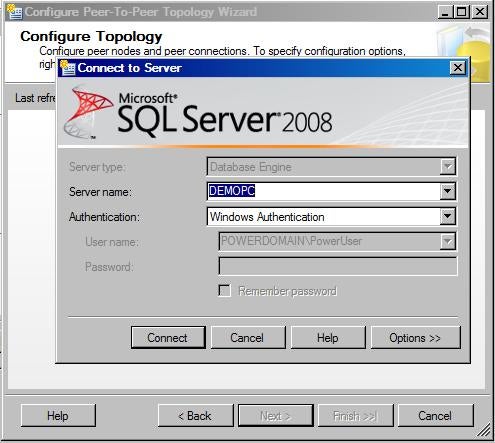
In the Connect to Server dialog box, connect to DEMOPC.
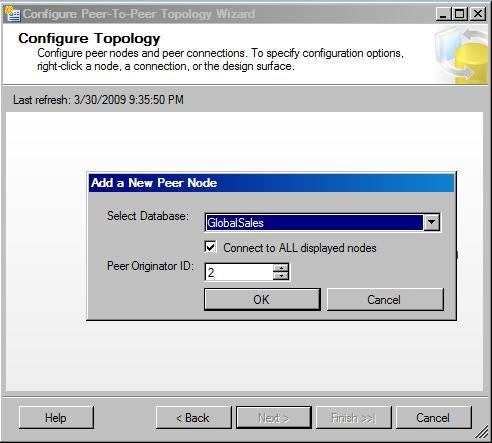
In the Add New Peer Node dialog box, select the GlobalSales
database and select Connect to ALL displayed nodes. Because the first
node POWERPC is already assigned the peer ID 1 automatically, specify 2 for the
second node DEMOPC in the Peer ID box.
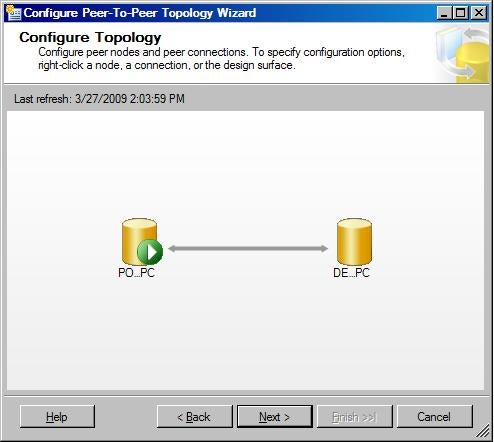
After clicking OK, DEMOPC now appears on the design
surface. It connects with POWERPC with a double arrow.
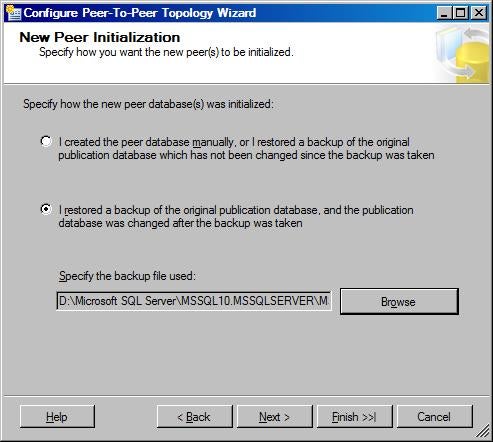
Follow the instructions in the wizard to set up the security
for the log reader and distribution agents. On the New Peer Initialization
page, select “I restored a backup of the original publication database, and the
publication database was changed after the backup was taken” and select the
backup on POWERPC that was used to initialize the GlobalSales database on DEMOPC.
Follow the instructions in the wizard to complete the
configuration. On the completion page, a summary is as shown below.
Configure all necessary publications and subscriptions at the
following Peer(s):
POWERPC
Create a push subscription to publication ‘[GlobalSales].[PubSales]’ on ‘POWERPC’ with the following options:
Subscriber: DEMOPCSubscription database: GlobalSales
Agent location: Distributor
Agent process account: Impersonate process account
Connection to Distributor: Impersonate process account
Connection to Subscriber: Impersonate process account
Synchronization type: Initialize from BackupDEMOPC
Create a peer-to-peer transactional publication with the following options:
Publication database: GlobalSales
Publication name: PubSales
Conflict detection: Enabled
Peer originator id: 2
Log Reader Agent process: Impersonate ‘SQLServerAgent service account’
Create a push subscription to publication ‘[GlobalSales].[PubSales]’ on ‘DEMOPC’ with the following options:
Subscriber: POWERPC
Subscription database: GlobalSales
Agent location: Distributor
Agent process account: Impersonate process account
Connection to Distributor: Impersonate process account
Connection to Subscriber: Impersonate process account
Synchronization type: Replication support only
As you can see above, on POWERPC, a push subscription is
created with DEMOPC as the subscriber. On DEMOPC, a publication of the same
name PubSales with the same schema and data is created. A push subscription is
also created on DEMOPC with POWERPC as the subscriber. This two-node
Peer-to-Peer replication is implemented as a two-node transactional replication
with each node publishing and subscribing to the other node. You can also see
that the Distribution Agents have been created as well.
POWERPC-GlobalSales-PubSales-DEMOPC-11 (on POWERPC)
DEMOPC-GlobalSales-PubSales-POWERPC-11 (on DEMOPC)
If you check the Customers table on DEMOPC, you will see it
has one data row now as the Customers table on POWERPC.
6. Test the replication by inserting a row on DEMOPC.
USE GlobalSales
INSERT INTO Customers (ID, FirstName, LastName, CountryCode)
VALUES (‘CHN-0001’, ‘Jie’, ‘Wang’, ‘CHN’)
This row is replicated to POWERPC within seconds. Now the
Customers tables on both servers have two rows. The replication latency can be
minutes depending on the geological distance and network speed between servers.
If you run into an error 10061 with the error message shown
below, it means that the distribution agent cannot find the port number the
other server is listening on.
Message: A network-related or instance-specific error has
occurred while establishing a connection to SQL Server. Server is not found or
not accessible. Check if instance name is correct and if SQL Server is
configured to allow remote connections. For more information see SQL Server
Books Online.
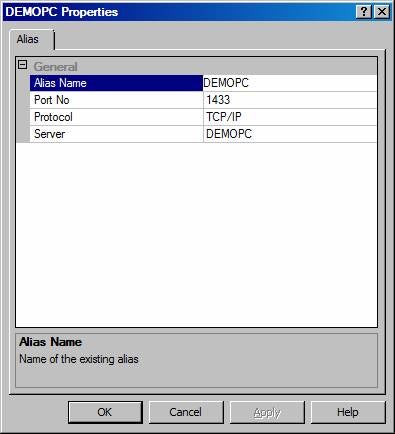
You will need to start up
the SQL Server Browser service. If that doesn’t work, then you can
configure a client alias.
Summary
In this article, we have shown you how to set up a two node
Peer-to-Peer replication topology. In the next article, we will add a third
node to the topology and demonstrate how to resolve an update-update conflict.