


By Tom Copeland
There is an understanding in the database world that using a
“SELECT DISTINCT” SQL query is not a good idea, because it is essentially
getting duplicate rows out of the database and then discarding them.
Usually it is better to rearrange the “WHERE” clause in the query to only
get the rows you need. One of these cases came up in a 3-way join query
in a PostgreSQL database I administer. This article gives a
step-by-step “case study” of analyzing a query in PostgreSQL and how to
ensure that your SQL rewrite is actually paying off.
Hunting for DISTINCTs
A SELECT DISTINCT query
is frequently a "code smell"; it indicates that something is not
quite right. That is because using the DISTINCT
keyword means that redundant data is being pulled from the database and then
discarded. Usually it is better to rewrite the query’s FROM and WHERE clauses to use a subquery to filter the data
correctly so that you only get back what you want.
After reading an
excellent article by Stephane Faroult on this topic, I went rummaging
around amongst the SQL queries inside the open source team collaboration tool GForge. Since I help administer a GForge server (RubyForge) that hosts over 400 projects and
1100 users, I am always happy to run across ways to help improve its SQL
efficiency. Hoping to apply my newfound knowledge, I used the UNIX tool egrep to search for DISTINCT in the source code:
$ egrep -r DISTINCT *
common/search/ArtifactSearchQuery.class:
$sql = ‘SELECT DISTINCT ON (a.group_artifact_id,a.artifact_id)
a.group_artifact_id,a.artifact_id,a.summary,a.open_date,users.realname ‘
common/search/ArtifactSearchQuery.class:
$sql = ‘SELECT DISTINCT ON (a.group_artifact_id,a.artifact_id)
a.group_artifact_id, a.artifact_id ‘
[…many more results skipped…]
A likely target turned up quickly in one of the hourly cron jobs. GForge has
a "mass mailing" component which is used for sending notices to
various groups of people (project administrators, site users, etc.) when
downtime is being scheduled or a new service is announced. The mass mailer
script was using a SELECT DISTINCT,
so it became the first optimization opportunity.
The query revealed
Here is the SQL query that looked like a likely target. GForge
aficionados will notice that I have selected just one of our several templatized
variations on this query, and that for the purposes of this article I dropped
the "paging" functionality that is part of the query since it is irrelevant
here. At any rate, this query selects the administrators of all the active projects:
SELECT DISTINCT u.user_id, u.user_name, u.realname, u.email, u.confirm_hash
FROM users u, user_group ug, groups g
WHERE u.status=’A’
AND u.user_id=ug.user_id
AND ug.admin_flags=’A’
AND g.status=’A’
AND g.group_id=ug.group_id
ORDER BY u.user_id;
It looks a bit complicated since it is doing a three-way join, but it is
really fairly straightforward. GForge has a users
table, a groups table, and a
user_group join table. Therefore,
to get the information we need, we join the three tables and filter out
inactive groups and non-administrative users. Since a user can be an
administrator of more than one project, we use DISTINCT to filter out duplicates; that way, someone does
not get a separate email for each project he administers.
Following the standard DISTINCT
elimination principles, I rewrote it to use an uncorrelated subquery:
SELECT u.user_id, u.user_name, u.realname, u.email
FROM users u
WHERE u.status = ‘A’
AND u.user_id
IN (
SELECT ug.user_id
FROM user_group ug, groups g
WHERE ug.admin_flags=’A’
AND g.status = ‘A’
AND g.group_id = ug.group_id
)
ORDER BY u.user_id;
So now there is a subquery that gets the user_ids
of all the active project administrators, and there is an outer query that
fetches the required information from the users table for each user id we
found. Note that it is an uncorrelated subquery because the inner query
does not reference the outer one. Also, note that we dropped a field – the confirm_hash field was not being used by
the surrounding code. That is another advantage to reviewing queries like this;
sometimes you can clean them up a bit in basic ways as well!
At this point, we want to ensure that the queries return equivalent result
sets. It is safe for us to run this on a live data set since this is a SELECT – if it were a DELETE or an UPDATE we would want to wrap it in a
transaction and then roll it back once the query was complete. In addition, in
this case, we can run it on the production database without unduly disturbing
anyone, because the query time is only around 10-20 milliseconds.
One way to test query equivalence is to pipe the output of both commands to
a file and use the UNIX diff
utility to check for, well, differences. Therefore, (after reinserting the confirm_hash field temporarily into the
new query to prevent all the output lines from differing) I put each query in a
small shell script and ran them both:
$ ./distinct.sh > res1.txt
$ ./subquery.sh > res2.txt
$ diff res1.txt res2.txt
No difference at all; that is what we want to see! Now we
know that the queries are functionally equivalent and we can move on to the fun
part – performance checking.
Analyzing with EXPLAIN
When tuning queries like this, it is best to check the before and after
performance of each query to ensure you are actually getting the expected
performance gains. GForge runs on the excellent open source database PostgreSQL, which has a fine query analysis
tool called EXPLAIN. The
PostgreSQL documentation contains copious
information on this tool, so I will not describe it fully here; suffice to
say that you can run EXPLAIN ANALYZE [your to see how the SQL execution engine (i.e, the planner and
query]
the executor) will run your query on the current database. Most importantly for
our purposes, it summarizes the results by listing the execution time in milliseconds.
So let’s see how fast the queries run; we will run each of them using another
small shell script:
[tom@rubyforge tom]$ cat check.sh
echo “DISTINCT”
psql -U gforge gforge -c “explain analyze
SELECT DISTINCT u.user_id, u.user_name, u.realname, u.email, u.confirm_hash
FROM users u, user_group ug, groups g
WHERE u.status=’A’
AND u.user_id=ug.user_id AND ug.admin_flags=’A’ AND g.status=’A’
AND g.group_id=ug.group_id ORDER BY u.user_id; ” | grep ms
echo “SUBQUERY”
psql -U gforge gforge -c “explain analyze
SELECT u.user_id, u.user_name, u.realname, u.email FROM users u
WHERE u.status = ‘A’ AND u.user_id
IN ( SELECT ug.user_id FROM user_group ug, groups g WHERE ug.admin_flags=’A’ AND g.status = ‘A’
AND g.group_id = ug.group_id) ORDER BY u.user_id; ” | grep ms
[tom@rubyforge tom]$ ./check.sh
DISTINCT
Total runtime: 20.509 ms
SUBQUERY
Total runtime: 12.507 ms
[tom@rubyforge tom]$
We can see that the new version is quite a bit faster than the old version. However,
was this just a fluke? Let’s run it a few times to make sure. An easy way to do
this is to use the UNIX watch
utility and the above shell script that executes both queries. Here is what it
looks like:
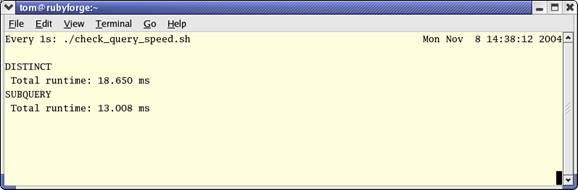
The screen clears and each query is run once every second. Since the output
is the same each time, the time in milliseconds stays in the same place on the
screen, so we can watch it for a while to make sure the results are consistent.
On RubyForge the query times did not vary
by more than a millisecond or so for 50-60 repetitions, so it seems like a
stable speed increase.
Now the obvious thing to do is to contribute this change back to the GForge
project so everyone can benefit. Best of all, since we analyzed the change, we
can present a patch with solid evidence that it will in fact improve
performance.
Conclusions
In summary, a SQL query that works can often be made more efficient. There
are general principles, which can be followed to attempt to increase query
performance, although each individual case should be checked to ensure it is
not an exception to the rule. Most databases have utilities to measure query
efficiency; with PostgreSQL, the EXPLAIN
command performs this task. Finally, when evaluating speed improvements, be
sure to use both queries on a representative data set so you will not get any
surprises when you deploy the query on your production database.
Credits
Thanks to Stephane Faroult, who wrote the article
that prompted this search for low-hanging fruit. Thanks also to Merlin Moncure
who reviewed this article and made many helpful suggestions.