


This should be easy!
Yes, deleting duplicates
should be easy, but it’s not. A Google search for newsgroup
posts about deleting duplicates scored over 2500 hits. Clearly, this is
a common problem.
The confusion is compounded, no doubt, by the existence of the built-in Find
Duplicates query wizard. While this wizard does a great job of helping you
identify duplicates, it does not provide a way to delete them. Many posts at
the newsgroup included frustrated comments like this: "I can see them,
but I can’t delete them!"
What are your options
I started researching this question after a friend asked
me how to delete duplicates in her database. The issue had never plagued me
personally, possibly because of the way I design my databases, but more
likely because my applications were simply not the type that tend to collect
duplicates. At first, I whipped up a quick VBA solution that met her specific
requirements, but over the years of watching newsgroup posts on the subject,
I realized there are several different ways to approach it. Here are some of
the suggestions I found:
-
Avoid creation of duplicates through tighter table and form
design.
(Excuse me for preaching but I just had to include that one.)
-
Use a SELECT query with a DISTINCT clause as the basis for a
MAKE TABLE Query. It will generate a new table of unique records to replace
the table with duplicates.
-
Write VBA code specifically designed to loop through a
particular table. Examine sorted records one at a time, comparing selected
fields and deleting duplicates as they are found.
-
Write generic VBA code to process any table. By iterating
through the fields collection, you can compare records without even knowing
the structure of the table.
I admit, telling you to avoid duplicates in the first
place is like shutting the barn door after the cows are long gone, but it
bears mentioning. If you do not find the reason for the duplicates, then this
process will become a regular maintenance task. How much better to fix the
problem before (or at least in tandem with) deleting duplicates.
The second point above is a creative suggestion that had been posted to the
newsgroups. I included it because of its simplicity and because I prefer
query solutions when possible. However, it does have some drawbacks.
It is not a very flexible-reusable solution. Specific queries MUST be
designed for each table with duplicates to be deleted. While this is not
difficult, it makes the process less portable to other databases. In addition,
it is not a one-step solution. You have to follow this process:
- Create
a SELECT DISTINCT query of records. - Create
a MAKE TABLE Query. - Run
the MAKE TABLE Query into Table2 - Delete
Table1 (and all its relationships) - Rename
Table2 as Table1 - Recreate
all relationships
My favorite solution
Just as I love query solutions because they’re clean,
I love VBA solutions because they’re cool. I know it’s geeky,
but I still get a thrill out of stepping through a recordset in code,
interrogating field values and metadata. That is what this solution to the
delete duplicates dilemma is all about.
The image below shows nearly all the code required. You will notice the word
Stop is highlighted in yellow. That command pauses the processing so you can
view the code and step through the process yourself. That is the best way to
learn what the code does. You can download
a copy of the code for this article and give it try yourself but basically,
this is the process:
- Load
a sorted recordset with the duplicate fields. - Loop
through the records, saving concatenated field values to a single variable. - Compare
the current field values with the previous ones. - When
duplicate is found, issue a DELETE command against the recordset.
The advantage of this solution is that you retain the
original table with all its relationships. Instead of replacing the table, you
are truly just removing unwanted records. For what it’s worth, this method
requires less processing and is more efficient, if only marginally so.
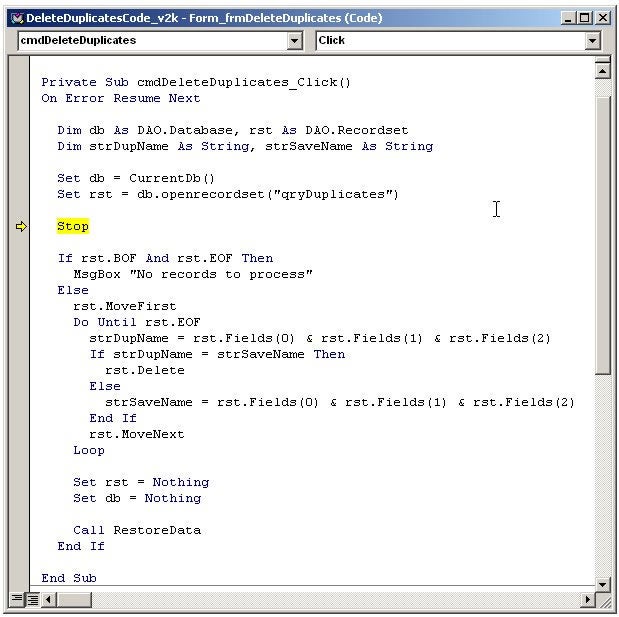
You’ll notice in this code that I’m referencing the fields using their
ordinal positions, with syntax that looks like this:
rst.Fields(0) &rst.Fields(1)
&rst.Fields(2)
I could just as easily have called the fields by name, but by using ordinals,
all you have to do to reuse this code is change the SQL statement used to
generate the recordset. While not completely table independent, it is pretty
flexible.
Alternate more flexible solution
This final suggestion is the most flexible and accurate.
Given any table, it generates a recordset of appropriate fields (excluding
memo and binary image fields) and dynamically loops through the fields’
collection to perform the recordset compare.
In this example, two recordsets are used, one being a clone of the other.
When a duplicate is found, it is deleted from the first recordset and the
next record is examined. When it has determined that the records do not
match, both recordsets are advanced. The code for this solution is shown
below. Copy and paste it into an Access module and try it.
Sub DeleteDuplicateRecords(strTableName As String)
‘ Deletes exact duplicates from the specified table.
‘ No user confirmation is required. Use with caution.
Dim rst As DAO.Recordset
Dim rst2 As DAO.Recordset
Dim tdf As DAO.TableDef
Dim fld As DAO.Field
Dim strSQL As String
Dim varBookmark As Variant
Set tdf = DBEngine(0)(0).TableDefs(strTableName)
strSQL = “SELECT * FROM ” & strTableName & ” ORDER BY ”
‘ Build a sort string to make sure duplicate records are
‘ adjacent. Can’t sort on OLE or Memo fields,though.
For Each fld In tdf.Fields
If (fld.Type <> dbMemo) And _
(fld.Type
<> dbLongBinary) Then
strSQL = strSQL & fld.Name & “, ”
End If
Next fld
‘ Remove the extra comma and space from the SQL
strSQL = Left(strSQL, Len(strSQL) – 2)
Set tdf = Nothing
Set rst = CurrentDb.OpenRecordset(strSQL)
Set rst2 = rst.Clone
rst.MoveNext
Do Until rst.EOF
varBookmark = rst.Bookmark
For Each fld In rst.Fields
If fld.Value <> rst2.Fields(fld.Name).Value Then
GoTo NextRecord
End If
Next fld
rst.Delete
GoTo SkipBookmark
NextRecord:
rst2.Bookmark = varBookmark
SkipBookmark:
rst.MoveNext
Loop
End Sub
As you can see, there are a number of ways to approach the
problem of duplicate records. Which one you choose will depend on your
specific needs, particularly on how automated a solution you desire. However,
in closing, I have one note of caution: Regardless of the method you use to
remove records, always make a backup before you begin!