


Rob Gravelle takes a
complex SQL statement and shows you several ways to re-write it that both
simplifies and shortens it, while still yielding the same results.
After the All
About the Crosstab Query article was published, some astute readers pointed
out that my SQL statement was more complex than it needed to be. Their
suggestions sent me in search of a simplified statement that would yield the
same results. There were a couple of ways to shorten and simplify the SQL – in
some cases, substantially. We will be reviewing the most effective solutions today,
which include using the CASE statement within the Count() function and the specialized
WITH ROLLUP GROUP BY Modifier.
The CASE Statement
The CASE statement is
a type of conditional construct much like an IF ELSE. It evaluates a search
condition and executes the corresponding SQL statement list, depending on which
condition evaluates to true. If no search condition matches, the statement list
in the ELSE clause is executed instead. Each statement list may consist of one
or more statements. Multiple statements are enclosed between the BEGIN and END
delimiters.
One Statement, Two Styles
There are two forms of
CASE statement, depending on whether you want to evaluate an object – such as a
column or variable – or the results of an expression. Here is the syntax for
evaluating an object:
CASE case_value
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list] …
[ELSE statement_list]
END CASE
Some Examples
Perhaps the simplest
use for the CASE statement is to categorize row data into categories. In the
following example, values in the term_number column are converted to their
associated description so that the results are meaningful to the end client.
Notice that there is no ELSE clause, because we never expect a value outside of
the 1 to 4 range:
SELECT CASE term_number
WHEN 1 THEN ‘Fall’
WHEN 2 THEN ‘Winter’
WHEN 3 THEN ‘Spring’
WHEN 4 THEN ‘Summer’
END AS ‘Term’
FROM class_schedule;
Another good time to
use a CASE statement is to choose a column based on a variable’s value, such as
a stored proc input parameter. Here, a language code is used to choose between
an English and French description. The ELSE is used to good effect so that any
code other than ‘F’ will default to English:
SELECT CASE @language_cd
WHEN ‘F’
THEN french_desc
ELSE english_desc
END AS ‘type_desc’
FROM vcode_value
WHERE code_value_id = assistance_request_type_cd;
The other form of the
CASE statement, which uses a search condition, is found most often because of
it’s greater flexibility. Here is the syntax for it:
SELECT CASE
WHEN search_condition THEN statement_list
[WHEN search_condition THEN statement_list] …
[ELSE statement_list]
END CASE
Some Examples using a Search Condition
One common use of the
CASE statement is to handle Nulls or empty values. In this instance, a value
of “Not supplied” is provided as a default value:
SELECT family_name,
given_name,
CASE WHEN state IS NULL OR state = ”
THEN ‘Not supplied’
ELSE state
END
FROM clients
There are many times
where either style can be utilized, but one is more readable and efficient to
write than the other. For instance, we could easily replace the previous
example using a search condition:
SELECT CASE WHEN @language_cd = ‘F’
THEN french_desc
ELSE english_desc
END AS ‘type_desc’
FROM vcode_value
WHERE code_value_id = assistance_request_type_cd;
Both work equally
well, but I personally find the search condition syntax to be slightly more
readable.
If there is an easy
rule of thumb that I can suggest for deciding between styles, it would be that
the first one is best for evaluating the same object against multiple possible
values, such as we did with the school terms. Hence:
SELECT CASE WHEN row_value = ‘A’ THEN ‘VALUE A’
WHEN row_value = ‘B’ THEN ‘VALUE B’
WHEN row_value = ‘C’ THEN ‘VALUE C’
WHEN row_value = ‘N’ THEN ‘VALUE N’
…
–is perhaps better expressed as
SELECT CASE row_value WHEN ‘A’ THEN ‘VALUE A’
WHEN ‘B’ THEN ‘VALUE B’
WHEN ‘C’ THEN ‘VALUE C’
WHEN ‘N’ THEN ‘VALUE N’
…
The latter version is
definitely more succinct.
Supplying the Results of a CASE Statement to the Count Function
The Count() function
is most commonly used with an asterisk (*), which tells it to count entire
rows. Another usage is to pass in an individual field. Doing so will cause the
function to count the number of non-NULL instances of that particular column.
This is the key to using a CASE statement with Count(), as we can use it to
select the FEE_NUMBER values where the REGION_CODE matches a value of ‘01’ to
‘05’. Here is the simplified SQL, without the final TOTALS row:
SELECT MONTHNAME(CREATION_DATE) AS ‘Month’,
COUNT(CASE WHEN REGION_CODE =’01’ THEN FEE_NUMBER END) AS ‘REGION 1′,
COUNT(CASE WHEN REGION_CODE =’02’ THEN FEE_NUMBER END) AS ‘REGION 2′,
COUNT(CASE WHEN REGION_CODE =’03’ THEN FEE_NUMBER END) AS ‘REGION 3′,
COUNT(CASE WHEN REGION_CODE =’04’ THEN FEE_NUMBER END) AS ‘REGION 4′,
COUNT(CASE WHEN REGION_CODE =’05’ THEN FEE_NUMBER END) AS ‘REGION 5’,
COUNT(*) AS ‘TOTAL’
FROM TA_CASES CA
WHERE YEAR(CREATION_DATE)=1998
GROUP BY MONTH(CREATION_DATE);
The WITH ROLLUP Modifier
Adding the WITH ROLLUP
modifier to the GROUP BY clause will append an additional row to the result set
which sums all columns. ROLLUP thus allows you to summarize data at multiple
levels with a single query. The grand total super-aggregate lines can be
identified by the Null values in the GROUPed BY fields. Hence the following query:
>SELECT year, SUM(profit) FROM sales GROUP BY year WITH ROLLUP;
…would produce
something like the following:
+——+————-+
| year | SUM(profit) |
+——+————-+
| 2000 | 4525 |
| 2001 | 3010 |
| NULL | 7535 |
+——+————-+
We can replace the Null
with a more suitable value such as “TOTAL”, but it isn’t easy, as the Null row
is inserted late in query processing. Another challenge is presented by working
with grouping on the output of date functions. For instance, grouping on the
MONTHNAME() sorts the rows in alphabetical order, rather than chronological.
The answer to both
these issues is a two pass approach. The first selects all of the fields that
we want, plus the month number, for sorting. We can select from it by placing
the code after the FROM of a second query. A CASE statement selects between
the Month column and the “TOTAL” label:
SELECT CASE WHEN Month_Num IS NULL
THEN ‘TOTAL’
ELSE Month
END AS ‘Month’,
REGION_1 AS ‘REGION 1’,
REGION_2 AS ‘REGION 2’,
REGION_3 AS ‘REGION 3’,
REGION_4 AS ‘REGION 4’,
REGION_5 AS ‘REGION 5′,
TOTAL
FROM (SELECT MONTH(CREATION_DATE) AS Month_Num,
MONTHNAME(CREATION_DATE) AS Month,
COUNT(CASE WHEN REGION_CODE =’01’ THEN FEE_NUMBER END) AS REGION_1,
COUNT(CASE WHEN REGION_CODE =’02’ THEN FEE_NUMBER END) AS REGION_2,
COUNT(CASE WHEN REGION_CODE =’03’ THEN FEE_NUMBER END) AS REGION_3,
COUNT(CASE WHEN REGION_CODE =’04’ THEN FEE_NUMBER END) AS REGION_4,
COUNT(CASE WHEN REGION_CODE =’05’ THEN FEE_NUMBER END) AS REGION_5,
COUNT(*) AS TOTAL
FROM TA_CASES
WHERE YEAR(CREATION_DATE)=1998
GROUP BY Month_Num WITH ROLLUP) AS CA;
The output of the
above query is a complete crosstab, including chronological row sorting and totals:
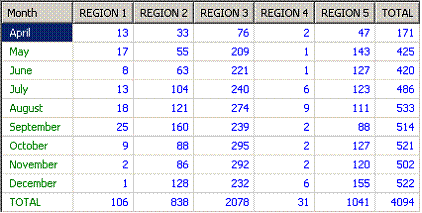
Cutting down the size
of the SQL will come in useful when generating the code within a stored proc.
Remember that the query itself is really quite a simple one as it only hits one
table, only pivots between two fields. As we shall soon see, not every
crosstab query is as straightforward.