


Simplify the monitoring of queries in Oracle Database with Oracle Enterprise Manager (OEM). Learn how to analyze query related activity and reach a definitive conclusion of database performance.
This document simplifies the monitoring of queries in Oracle Database with Oracle Enterprise Manager (OEM). The purpose of this paper is to show quickly how we can analyze query related activity and reach a definitive conclusion of Oracle’s performance. Active Session History (ASH) is explored to show if the workload on Oracle is beyond its support limit. Query snapshot is explored to show greater detail and to allow us to guesstimate when a given query is likely to complete.
Snapshot
Most of us are familiar with a saying ‘If you do not know where you are going, any road will get you there’. The same thing goes with Oracle Database when it comes to monitoring or troubleshooting. One can spend hours or days without knowing what happened, if we do not focus on the situation at hand. You have probably also heard, “let us throw more CPU and hardware at the problem, all will work well”. In general, this can be a valid assumption, but not always. Adding more horsepower to solve a system problem can result in more contention as CPU churns out more data, thereby choking the system. If you have an Oracle query problem, OEM is most likely the answer.
Oracle Enterprise Manager (OEM) is a single interface that greatly enhances our ability to monitor and diagnose queries. A few tools are included within OEM interface that allow us to look deeper to get a better snapshot at a particular query. It is important to know that OEM has changed from Oracle 10g to 11g. OEM query monitoring is straightforward in understanding what is happening at Oracle level. If one is monitoring at a low level, such as byte or block view, third party tools are available in the market, OEM is not the best option in this case.
Journey
Start your journey by logging into OEM. I assume that you have Oracle and OEM configured correctly, and everything works as expected. Since this is a web interface, anyone can click through various navigational links to study details. This is not challenging to most of us as we have sufficient database background. In my case, I am using an Oracle Database 11g R2 on a 4-node RAC with 256 Gig on each 24 core CPU, using high end 1 TB of cache at storage, in a DW environment. This is a ‘near’ production environment with high or even higher workload compared to real systems. Though configuration details are irrelevant, statistics that you notice in subsequent sections can be related back to this environment.
At the home page, you can quickly skim through a couple of important particulars.
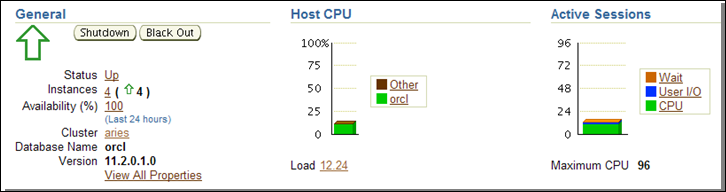
Figure 1
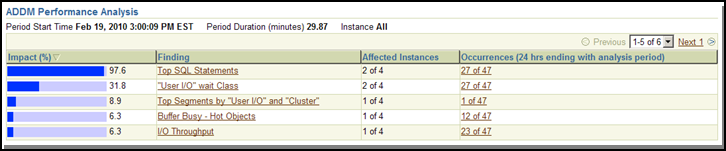
On the same page, towards the lower bottom, OEM displays high resource hitters with ADDM findings. These are sorted by total impact to the Oracle environment. Here are two such snapshots taken at different times.

Figure 2
The snapshot above is quite different from the ADDM findings at a different time. As can be seen below, only two instances are experiencing these symptoms. You can click on the Findings link to see details, but since our focus is on queries, we will skip that part.
Click on the Performance link on the top of the page, shown below for reference.

Figure 3
This takes us to the next web page. This page has important particulars for monitoring and quick diagnosing across all Oracle instances. If you have not already done so, please spend some time on all sections of this web page. This knowledge is useful in many troubling circumstances. We can go back in time using View Data on the top right corner dropdown box.
My focus always goes first to Average Active Sessions (See Figure 4). This graph is placed appropriately at the center of the page, signifying the high importance of this graph. We first check to see if our system is within the workload. This graph shows a snapshot of the system workload, including what is contributing to performance delays. All factors are stacked together to show if our system is within the workload. Each value that is represented in this graph on the Y axis is derived from values Oracle uses internally. In other words, it is not easy for us to manually calculate the value of Y axis. X axis is time based, we can relate to this easily. This graph shows up to 160 at any time. Why each component (color portion) gets a certain value is not explained by Oracle. This value depends on various factors such as load on the system, CPU and memory utlization, etc. If all stacked factors are within an acceptable range, the graph should be below the red line. Reference A has further discussion on this topic based on extensive work carried by Kyle.
High workload scenario
For illustration purposes, I am using only two nodes effectively, through the creation of a service, yet our system shows the workload beyond the maximum CPU mark. Since our environment is a 4 node RAC, with only 2 nodes in use, that gives 2 x 24 CPU = 48 CPU. In other words, the load is excessively high and it should not cross beyond 48 points on this graph. Oracle arrives at these numbers through internal algorithms that closely related CPU usage and other resources.
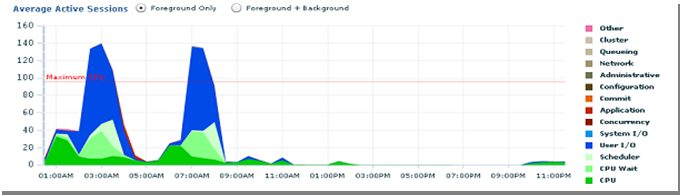
Figure 4
In the following picture, the same RAC is shown with a different workload on the system. This is within workload limits.
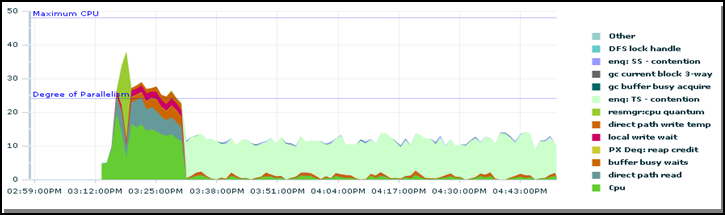
Figure 5
Here is the same four node RAC, operating within its workload limits.
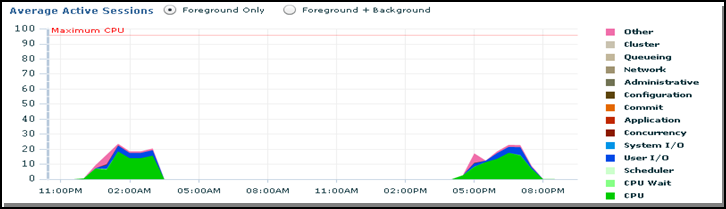
Figure 6
We can also monitor other factors such as throughput, I/O activity, parallel execution at node level involving interconnect, services (for instance, 4 node RAC can be divided to support 2 nodes for batch service and other 2 nodes for ad hoc queries) and instance level monitoring. As mentioned above, we want to lead our journey to query monitoring.
![]()
Figure 7
Please click on these links above (from OEM) to see corresponding activity. Reference B is a good source for this area.
Query Monitoring
Towards the bottom of the page, we notice the Query Monitoring link. Just to recap, after logging into OEM, click on the Performance tab to see this link. This link allows us to monitor all active queries, in addition to previously run queries.

The next screen is where all query details are presented in an easy to understand manner. One can drill down further to reach corresponding pages where additional information is presented. Note that we can either limit to the last five minutes or extend all the way to a day so that we can look at queries in those periods. Likewise, we can stop refresh or adjust refresh of query details. This comes in handy when the system is too busy with heavy ad hoc queries.

Figure 8
Shown below is one entry in the SQL execution table in this window. Depending on the system load, there can be multiple queries.

Figure 9
The above screenshot are the following values:
- Query status is active, displayed with a green line halo.
- It has been running for the past 10 hours.
- Running on instance 4, SQL ID and user name indicated. If running on other instances or nodes, this is where it started.
- Running with 24 parallel threads, using only one instance. That is, no inter node traffic, in a way.
- Database time, IO requests, start & end time, and SQL text are indicated in this table.
- Double clicking on SQL ID, in this case, 8bysvy84skdp3, takes us to our destination. One can certainly travel farther to explore and reach higher enlightenment. For our purpose, we are at our final stage.
- Degree of Parallelism is set at 24 for this query, at resource manager level. Though you can set this parameter using dbms package commands through sqlplus, I find it very helpful to use the OEM web interface to change this.
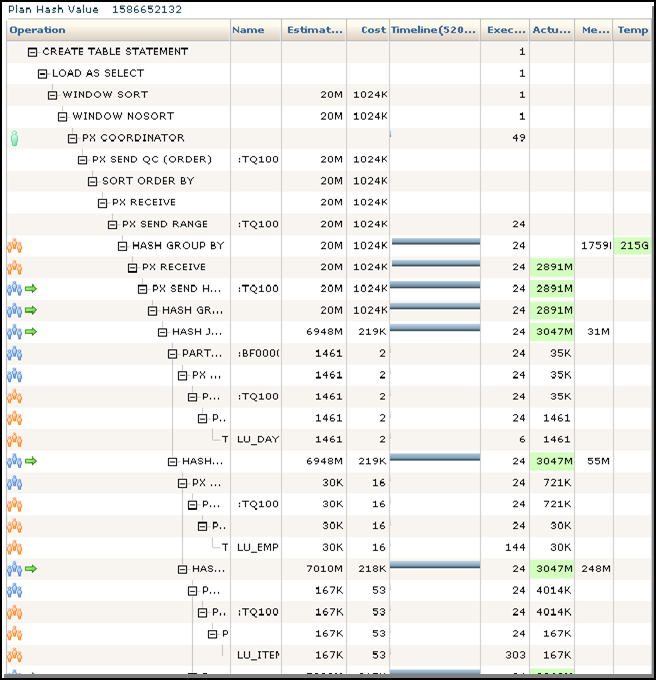
Figure 10
Simplified query plan
This query does a simple join of four tables, one of which is a big fact table and the rest are dimension or lookup tables. Since all rows are used in all tables (there are corresponding matching rows for each row in the big fact table), it involves receiving data starting from the fact table. Here is a simple flow:
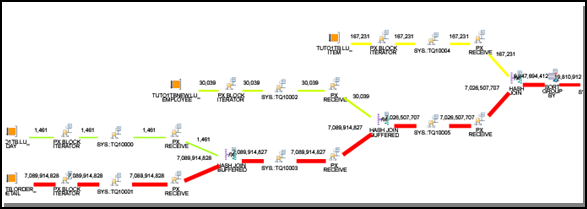
Figure 11
Steps involved at a higher level:
- Read from a table: Parallel processing by reading from that table, this is shown at leaf level.
- Read from another table, if applicable -: Parallel reading with hash joins. This acts as input to the next iteration, if applicable.
- Keep doing above until there are no more tables.
All of the above joins use hash joins, with final level sorting and grouping. Note that there is no WHERE condition for this query. As a general observation, hash joins are extremely popular with data appliances including Teradata. One advantage of the hash join is that typically no ordering or sorting is needed before the join takes place.
A few important items to look at in this screen shot. Due to page limitations, not all steps in this query are visible.
- Left column indicates that all operations are parallelized; this is indicated by icons on the left. Blue and orange indicates sender and receiver, based on Oracle parallel processing.
- We know which step Oracle is processing by a green arrow point on the left and corresponding green flash on the right of most columns.
- We know how long this query is expected to last based on estimated rows and actual rows columns. This is mostly accurate based on how up to date statistics are and how Oracle optimizer is gathering particulars in its interpretation.
- Query is indicated in a reverse tree hierarchy. This query as explained above, does not contain a WHERE clause and involves hash joins.
References
- Session History (ASH) by Kyle. Series of documents produced by Kyle are available on internet.
- Oracle 11g documentation.
- Documents from Jonathan Lewis on Oracle parallel execution.
About Author:
Srinivasa Meka worked for many years on very large database implementations. His background includes Oracle 9i through 11g R2, Teradata 6 & 13.x, Netezza 3.x through 5.x, Datallegro, Ingres / Postgres, Red brick and a bit of Sybase / SQL server. Unique skill sets include database design in both OLTP and OLAP with data modeling knowledge, with strong enough UNIX system background. He can be reached through srini underscore nova, at yahoo dot com.
Note that all opinions expressed are those of the author; do not reflect that of any employer that the author work or worked for.