


The Oracle RDBMS is
obviously a data source for itself, and when a user wants to get data from the
database, there is a litany of features and options to consider. Permissions,
roles, grants, tables, views, synonyms and database links are commonly seen.
Perhaps less obvious are other data sources within the database, and one in
particular is the materialized view (or snapshot in older days). In this
article, we’ll take a quick look at the materialized view and extend the
concept of that feature to a case when Oracle is the data source for another
relational database management system.
Ignoring the initial setup,
how is a materialized view populated, updated or refreshed? You have several
options, with the two extremes ranging from “do it when I say so” (ON DEMAND)
to “do it whenever a change is made” (ON COMMIT). The “what” in where the
change is made (or being pulled from) is known as a master table (or a detail
table if dealing with a data warehouse). The database source is also then known
as the master database as it contains the master tables.
When managing materialized
views, some of the privileges required include CREATE MATERIALIZED VIEW (for
working within your own schema) and CREATE ANY MATERIALIZED VIEW (for creating
these in other schemas). If query rewrite is involved, then QUERY REWRITE is
necessary at your own level and GLOBAL QUERY REWRITE if working outside your
schema. Just by being able to create objects in your own schema implies a slew
of object privileges.
Now, what if the Oracle
RDBMS, or more specifically, an Oracle database, serves as the master database
for another database system? What privileges would be necessary within Oracle
(for a given schema) in order to push data to say, a SQL Server database? If
data can be pushed from Oracle into SQL Server, then you wouldn’t be wrong in
assuming that data can be pushed from SQL Server into Oracle. In SQL Server
terminology, the Oracle database is referred to as either the publisher or
subscriber, and the direction in which data flows (from SQL Server’s
perspective) is known as a publication or subscription.
Starting with Oracle as the
publisher (data being pushed from Oracle to MSSQL), what is needed on the
Oracle RDBMS side of things? The process (from MSSQL’s side) can be looked at
as creating a replication user within Oracle. It’s not all that exotic in terms
of what is granted to the Oracle user/schema, and the list of grants includes:
-
Create public synonym (and drop
public synonym) - Create procedure
- Create sequence
- Create session
- Create any trigger
- Create table
- Create view
Microsoft provides a script to perform these steps, and the script (oracleadmin.sql) can be found in the
<drive>:\Program Files\Microsoft SQL Server\<InstanceName>\MSSQL\Install
folder. The “InstanceName” part of the path may be confusing if you’re not familiar with the installation footprint of SQL Server, but to make it simple, if all you’ve installed is the MSSQL server software for the instance (which contains multiple databases), then “InstanceName” is likely to be MSSQL.1.
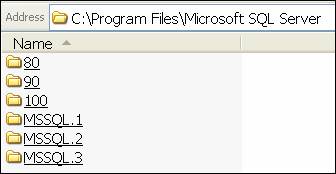
In the folder listing above,
the 80, 90 and 100 are related to versioning of SQL Server, with 80
corresponding to SQL Server 2000, 90 for 2005, and 100 for 2008. The “MSSQL.X”
folders relate to what was installed feature-wise. In the example above, the
“2” and “3” correspond to Analysis Services and Reporting Services, and the
order can go either way: it just depends on which feature was installed
first/in a later configuration run.
In the script provided by
Microsoft, the Oracle user is referred to as a replication user because that is
essentially what is taking place here: data is being replicated from Oracle to
SQL Server. If the replication user is the conduit through which data from
Oracle flows into SQL Server, what other privilege do you think may be needed
for this user? Data changes in schema X, but how does the replication user know
that in terms of being able to see the data in the other schema? Reading the
script is useful here because a comment at the end tells us what else is
needed: the replication user needs to have select privileges on the other
tables. If you want a table in the Scott schema to be replicated into a database
in a SQL Server instance, then Scott needs to have granted select on that table
to the replication user.
The replication user in
Oracle winds up with the following collection of objects once the SQL Server
setup is complete (to be covered in a subsequent article). The count by object
type is:
|
Object |
Count |
|
Table |
11 |
|
Sequence |
3 |
|
Package/package body |
1 |
|
Synonym (public) |
1 |
|
Function |
1 |
|
Procedure |
2 |
|
Trigger |
2 |
|
View |
2 |
All of the object names are
prefaced with HREPL, which suggest heterogeneous replication, which makes sense
since the sources are different. A complete listing of the objects
and their function or purpose can be found in the Books Online
documentation. Much of what is created in the replication user schema is
analogous to how Oracle operates materialized views.
The list of steps provided
by Microsoft include:
1. Create
a replication administrative user within the Oracle database using the supplied
script.2. For
the tables that you will publish, grant SELECT permission
directly on each of them (not through a role) to the Oracle administrative user
you created in step one.3. Install
the Oracle client software and OLE DB provider on the Microsoft SQL Server
Distributor, and then stop and restart the SQL Server instance. If the
Distributor is running on a 64 bit platform, you must use the 64 bit version of
the Oracle OLE DB provider.4. Configure
the Oracle database as a Publisher at the SQL Server Distributor.
For Step 1, running the
oracleadmin script is quick and it exits at the end. My example uses
MSSQLDIST/oracle for the replication user and password, and the USERS
tablespace as the default tablespace. For Step 2, use a convenient schema such
as SCOTT and issue (as Scott):
grant select on dept to mssqldist;
grant select on emp to mssqldist;
grant select on bonus to mssqldist;
grant select on salgrade to mssqldist;
For Step 3, install the
Administrator level version of Oracle client software (no need to bother with
any other level) on the SQL Server host. Being Windows, this is a very
straightforward process.
Step 4 will be covered in
part two, as it is a bit more involved. One of the gotchas in this process is
the version of SQL Server being used. A non-SQL Server publisher is supported
only in the Enterprise and Developer editions. If using the standard
edition, then sorry, you will be out of luck when at the final “click OK” steps
of configuring the publisher.
In Closing
Once the configuration for
replication is complete, it is interesting to see data flow back and forth
between two different database systems. Oracle software is entirely free for
educational (your own, that is) purposes, and SQL Server is free for a while
(180 day evaluation period). The download for SQL Server 2005 is here,
and the page contains links to getting 2008. If you are running Windows XP
Professional on a personal computer, along with a decent amount of memory (if
you can run Oracle okay, you can run SQL Server as well), you have enough to
get started on configuring replication between Oracle and SQL Server, and part
two will go into more detail about this process.