


Introduction
Grouping records is the process of combining like SELECT columns together. Once combined, Aggregate functions such as SUM and AVERAGE can be performed on the set. This article will examine several SQL Server 2008 grouping functions including GROUP BY, GROUPING SETS, CUBE, and ROLLUP. In addition, we’ll demonstrate how to use SUM and COUNT in a WHERE clause after rows have been grouped.
DISTINCT
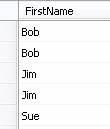
Before beginning a review of grouping functions, we’ll introduce the TSQL keyword DISTINCT because one of first questions usually asked when discussing grouping is “what is the difference between GROUP BY and DISTINCT?” DISTINCT is a TSQL keyword that will remove duplicates from a record set. For example, in the following table of first names, the return of a DISTINCT statement is shown.
SELECT DISTINCT FirstName from Names;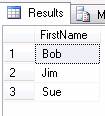
So although there are five rows in the table, only three records are returned. The DISTINCT keyword has removed any duplicates. It may be helpful to think of DISTINCT as meaning “the removing of duplicate rows”. The rows have not been grouped in the sense that we could ask “how many Bob first names are there.” For that we would need a “GROUP BY” statement rather than DISTINCT. DISTINCT simply removes duplicates and presents a list of what remains.
GROUP BY
The TSQL key word GROUP UP combines like selected rows together in a summary row. Here is the above statement rewritten with a GROUP BY.
SELECT FirstName FROM Names GROUP BY FirstName;
The results are identical to the DISTINCT example. The reason for using GROUP BY rather than DISTINCT is the ability to use Aggregate functions such as COUNT and SUM. Here is the same query as above but including a count of how many times each name appears.
SELECT FirstName, COUNT(*) FROM Names GROUP BY FirstName;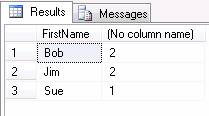
Aggregates
There are several aggregate commands that are frequently used with GROUP BY.
AVG – Returns the average value of a grouped column.
COUNT – Returns the number of times the time appears in a column.
MAX – Returns the single greatest value in the grouped column.
MIN – Returns the least great value in the grouped column.
SUM – Returns the calculated total.
For a complete list of Aggregates, see Books On Line: Aggregate Functions Transact-SQL.
GROUP BY
This next example will be run on the SQL 2008 Adventure Works LT database. Adventure Works is a free test database that can be downloaded from Microsoft.
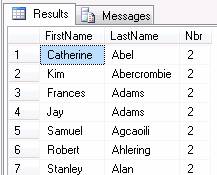
When multiple columns are selected, they must also be included in the grouping. For example, if both the First Name and Last Names were selected, then the grouping would need to include them as well, as shown below.
SELECT FirstName, LastName, COUNT(*) AS Nbr
FROM SalesLT.Customer
GROUP BY FirstName, LastName;
As an aside, Aggregates can be used without an explicit GROUP BY statement, creating an implied GROUP BY as shown below:
SELECT COUNT(*) AS Nbr
FROM SalesLT.Customer
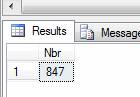
For this to work though, only the Aggregate can be Selected, no other columns.
GROUPING SETS
GROUPING SETS are a new feature of SQL Server 2008. Using them will allow multiple groupings to be returned in one record set. This example will group twice, once on SalesPerson , the second time on the table as a whole.
SELECT SalesPerson, COUNT(*) AS Nbr
FROM SalesLT.Customer
GROUP BY
GROUPING SETS
(
(SalesPerson),
()
);
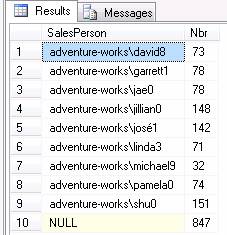
The last row with a SalesPerson name of NULL is the total Count. We could rewrite our statement using CASE to replace the NULL value with a more readable output.
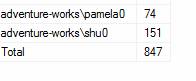
SELECT [Sales Rep] =
CASE WHEN SalesPerson IS NULL THEN ‘Total’
ELSE SalesPerson
END
, COUNT(*) AS Nbr
FROM SalesLT.Customer
GROUP BY
GROUPING SETS
(
(SalesPerson),
()
);
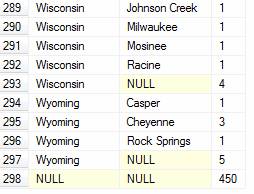
In this next example, based on the “Address” table, the Grouping Set creates three summary levels. Giving us the number of records located in the same City + State, the count of same State, then a Grand Total of all.
SELECT StateProvince, City, COUNT(StateProvince) AS Nbr
FROM SalesLT.Address
GROUP BY
GROUPING SETS
(
(StateProvince, City),
(StateProvince),
()
);
UNION
UNION is a TSQL keyword for combining multiple Select statements into one result set. UNION was one of the methods used for creating summary rows before GROUPING SETS existed. Below is the above State + City example but rewritten using a UNION.
SELECT StateProvince, City, COUNT(StateProvince) AS Nbr
FROM SalesLT.Address
GROUP BY StateProvince, City
UNION
SELECT StateProvince, NULL AS City, COUNT(StateProvince) AS Nbr
FROM SalesLT.Address
GROUP BY StateProvince
UNION
SELECT NULL AS StateProvince, NULL AS City, COUNT(StateProvince) AS Nbr
FROM SalesLT.Address
ORDER BY StateProvince DESC, City DESC
Each statement combined with a UNION must have the same number of columns. That’s why the last two groups use NULL as column placeholders.
CUBE and ROLLUP
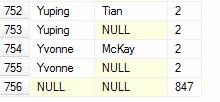
Before GROUPING SETS, CUBE and ROLLUP were also used to create summary rows. Both are extensions of the GROUP BY statement. The example below using ROLLUP creates a summary row for each group of First Names and a Total Row at the bottom.
SELECT FirstName, LastName, COUNT(*) AS Nbr
FROM SalesLT.Customer
GROUP BY FirstName, LastName
WITH ROLLUP
WHERE – HAVING
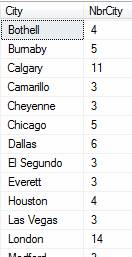
Aggregates such as COUNT can be used as a filtering clause, like a WHERE statement, in addition to being included in a SELECT list. Because aggregates are derived from a GROUP BY, their syntax is different from a regular WHERE statement. Instead, there is a special keyword, HAVING. As an example, a statement selecting only Cities that have COUNTs greater than two is shown below.
SELECT City, COUNT(City) AS NbrCity
FROM SalesLT.Address
GROUP BY City
HAVING COUNT(City) > 2
Conclusion
Grouping in SQL Server allow a single statement to return aggregated totals as well as discreet rows in one record set. The new GROUPING SETS command creates TSQL statements that are more readable and easily understood compared with multiple UNION statements or CUBE and ROLLUP. The DISTINCT keyword, while handy for use in a SELECT returning only unique value, cannot be used for totaling. Lastly, to filter on GROUPED totals, use the HAVING clause.