


Introduction
Microsoft introduced Azure SQL Data Warehouse, a new enterprise-class, elastic petabyte-scale, data warehouse service that can scale according to organizational demands in just few minutes. In my first article of the series, I talked about traditional ways of creating data a warehouse and the challenges with it in the current scenario, then discussed Azure SQL Data Warehouse, and how it helps in meeting the changing demands for the current business. In my second article of the series, I covered the architecture of Azure SQL Data Warehouse in detail and how you can scale up0 or down based on your need. In this article I am going to talk about the different types of tables we can create in SQL Data Warehouse, how they impact the performance and best practices around them. We will also get started with creating our first SQL Data Warehouse database, etc.
SQL Data Warehouse – Type of Tables
As of now, based on data distribution, there are mainly two types of tables that we create in SQL Data Warehouse, hash distributed and Round-Robin tables.
Please note, Microsoft is working to include a third type, replicated table, which we can expect to have in the future.
Round-Robin Table
This is the default distribution type for a table in SQL Data Warehouse and as its name implies, the data for a round-robin distributed table is distributed evenly (or as evenly as possible) across all the distributions without the use of a hash function. As data gets loaded, each row is simply sent to the next distribution to balance the data across distributions.
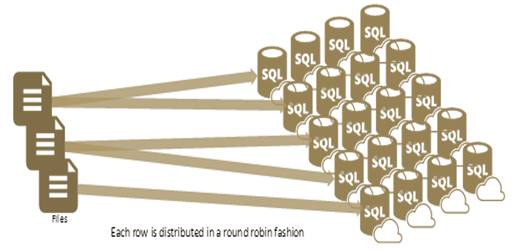
Each row is distributed in a round robin fashion
Round-robin tables do not exhibit signs of data skewness among distributions. This is because the data will always be randomly distributed evenly across all of the distributions. Usually common dimension tables or staging tables or tables that doesn’t distribute data evenly are good candidates for round-robin distributed tables.
Hash Distributed Table
One of the key points with SQL Data Warehouse is the hash distributed table, which is based on MPP (Massively Parallel Processing) architecture and helps you achieve the storage and query processing benefits of the Azure SQL Data Warehouse. Data for the hash distributed table gets distributed across multiple distributions and eventually gets processed by multiple compute nodes (based on size of your database tier) in parallel across all the compute nodes. Usually fact tables or large tables are good candidates for hash distributed tables. You select one of the columns from the table to use as the distribution key column when creating a hash distributed table and then SQL Data Warehouse automatically distributes the rows across all 60 distributions based on distribution key column value.
| Note – In SQL Data Warehouse, a distribution is an Azure SQL database in which one or more distributed tables are stored. Each instance of SQL Data Warehouse has many distributions (60 distributions for each table as of this writing). Many distributions can reside in a single Azure SQL instance though. In the next article, we will look into a query which shows distributions for a table. |
SQL Data Warehouse automatically assigns each incoming row to the right distribution (or basically storage location) based on the hash function. As discussed in the earlier article, SQL Data Warehouse leverages DMS to hash distinct values from the distribution key column and assigns each distinct value into one of those 60 distributions.
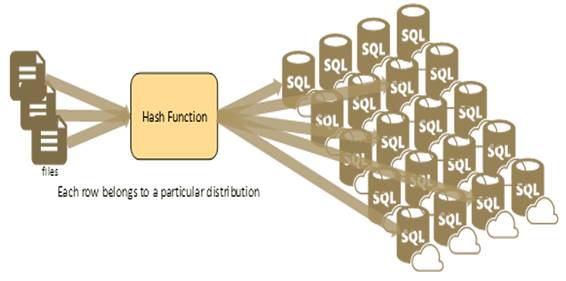
Each row belongs to a particular distribution
Data Skewness
You can start with a round-robin table when you do not understood your data yet or when you have no clarity on an obvious joining key for most of your queries. Though SQL Data Warehouse needs to invoke a data movement operation to better organize your data before it can resolve a query involving this table, as for this table the data is randomly distributed across all the distributions.
On the other hand, for a hash distributed table, data is distributed across distributions based on hashing of the distributed key column values. The hash function uses the distribution key column values to assign rows to distributions. The hashing algorithm and resulting distribution is deterministic in this case; that is the same value with the same data type will always go to the same distribution.
To summarize, though there is no data skewness with round-robin table, but performance will be hit because of data movement for all queries whereas in the case of hash distributed tables, the performance is much better for queries with compatible joins but there is a possibility that data will get skewed if the distributed key column is not chosen wisely.
Choosing the Right Hash Distribution Key Column for a Hash Distributed Table
Choosing the right distribution key column on which data should be distributed across different distributions plays a very important role. When you design your hash distributed table, there are some important considerations that you need to take while choosing the distribution key column:
- Data distribution – You need to ensure that the column that you choose for distribution key has a maximum or higher number of unique values. This is to ensure your data gets distributed evenly across all the compute nodes in order to have a good query parallelization across compute nodes. Contrary to that if you choose a column which has values unequally distributed, it will have data skew-ness. For example, if there are high number of NULL values for the distribution key column, one compute node might end up processing all the data (as all those NULL values will end in a single distribution) and will become bottlenecked in the parallel query performance.
- Compatible Joins – Data movement over the network is one of the most expensive operations and this is where compatible joins might help. With the help of compatible joins, you ensure you have all the data needed to process the portion of a query on the local compute node. To achieve this high performance, whenever possible you need to design your tables and queries in a way it does not require data movement. SQL Data Warehouse can achieve high performance by performing joins in parallel on the compute nodes and then combining the results on the control node. To improve query performance, tables and queries need to be designed so that, whenever possible, it is not necessary to move data (or minimize data movement at least) prior to the join. For example, if table Employee and EmployeeDemographics are distributed on column EmployeeKey and both of these columns have matching data types, then the following join is compatible: SELECT * FROM Employee E JOIN EmpployeeDemographics ED ON E.EmployeeKey = ED.EmployeeKey whereas SELECT * FROM Employee E JOIN EmployeeDemographics ED ON E.BirthDate = ED.BirthDate is not compatible as BirthDate is not a distribution key column in either table and will require data movement across nodes. Join incompatibility might arise even when two tables are distributed on different distribution key columns, and these distribution key columns are used in the joins. For example, one table is distributed on CustomerKey and other one is distributed on TransactionDate.
|
Notes – When processing queries involving distributed tables, SQL Data Warehouse instance executes multiple internal queries, in parallel within each SQL instance, one per distribution. These separate processes (independent internal SQL queries) are executed in parallel to handle different distributions during query execution or data load processing. |
In summary, you need to select a column for the distribution key, which ensures that the data gets distributed evenly across for parallel processing and which satisfies most of your queries for join compatibility and for better query performance.
Though, there might be a situation with a contradictory requirement, in that case you can re-create a table with a different distribution key and see which one suits to your specific need. SQL Data Warehouse has CTAS (CREATE TABLE AS SELECT) process, which allows creating tables with a different distribution key column with the same set of data very quickly as it runs in parallel.
Guidance to Choose Between Hash Distributed Vs. Round-Robin Distributed
These are some best practices and guidance, which will help you to decide the type of distribution for your tables in SQL Data Warehouse:
|
Hash Distribution |
Round-Robin Distribution |
|
The selection of the distribution key column is done by taking into consideration certain factors like minimizing the data skewness, minimizing the data movement for most of the joins, and types of queries executed on the system. |
Usually common dimension tables or tables that don’t distribute evenly or smaller lookup tables are good candidates for a round-robin distributed table. |
|
A nullable column is a bad candidate for any hash distributed table; likewise, an updated column to be used as a distribution key column is not a good fit. |
When the table is a temporary staging table or there is no obvious joining key then a round-robin table makes sense. |
|
A column with default constraints is usually not a good candidate for a distribution key column of a hash distributed table as it will introduce data skewness. |
When the table does not share a common join key with other tables or the join (in the query which you are optimizing) is less significant than other joins in other queries, again a round-robin table is to go for. |
|
The hash distribution key should contain significant distinct values for evenly distribution across. |
Round-robin tables typically provide balanced execution. This is because the data is stored evenly across the distributions. |
SQL Data Warehouse – Getting Started
Though there are multiple ways to create an Azure SQL Data Warehouse database, on the Azure Portal there are two options. First click on “+ New” icon on the left of the Azure Portal and click on “Databases” and finally select “SQL Data Warehouse” as shown in the figure below and then click on the “Create” button on the proceeding screen:
|
If you don’t have Azure Subscription already, you can get started with a free trial from here: https://azure.microsoft.com/en-us/services/sql-data-warehouse/extended-trial/ |
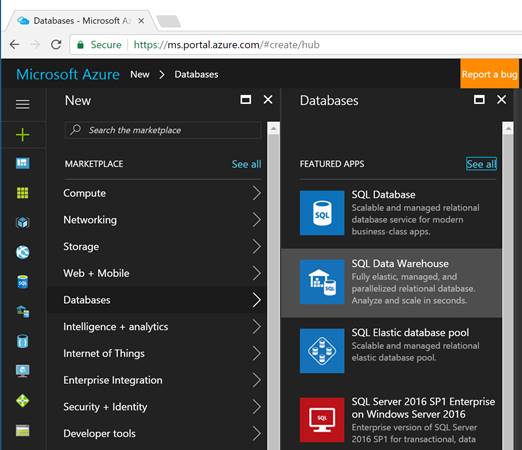
Create an Azure SQL Data Warehouse database – option 1
The second option is to click on “+ New” icon on the left of the Azure Portal and then type “SQL Data Warehouse”. The Azure portal will list all the offered services matching your input; now select “SQL Data Warehouse” as shown in the figure below and then click on “Create” button on the proceeding screen:
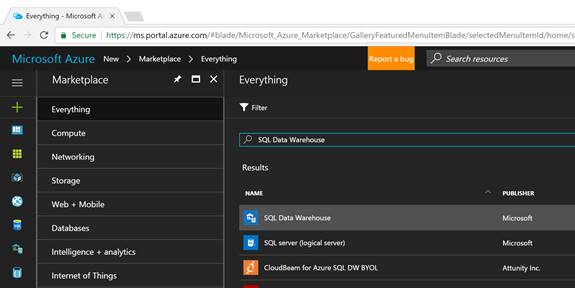
Create an Azure SQL Data Warehouse database – option 2
On the next screen, you need to specify a couple of things:
- Database Name – This is name of the database you want to create.
- Subscription – This is the Azure subscription you want this database to be created in; if you have access to multiple Azure subscriptions, you need to choose the right one to start with.
- Resource Group – You can think of Resource Group as a logical container for resources that share the same lifecycle, permissions and policies.
- Select Source – This allows you to specify where you want to start with this database, and you have these three options:
- Blank – This lets you create a blank database to start from the scratch.
- Backup – This lets you create or restore a database based on a previously taken backup.
- Sample – This lets you create a database based on AdventureWorksLT sample database.
- Server – A SQL Server in Azure is a logical server. If you already have a server, you can use that to create your database on or you can create a new server and then create the database on that.
- Collation – This lets you specify collation for your database though default collation is SQL_Latin1_General_CP1_CI_AS and you can change it to any valid collation type.
- Performance – With this you determine the performance of your database in terms of compute required. You can use the slider to increase or decrease the size and accordingly it will show you cost per hour based on your selection. As mentioned earlier, you can scale up or down your SQL Data Warehouse database anytime when there is a need. Also you can pause the database, releasing compute resources completely and only paying for storage when your database is not in use.
Once you are done with specifying all these values, hit the Create button to start provisioning your SQL Data Warehouse database. It will take a couple of minutes and will show you the progress on the dashboard, by default.
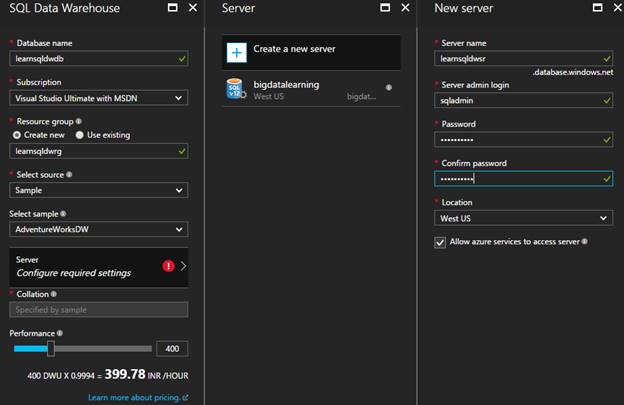
Create a new server
Once your SQL Data Warehouse database is created, you can browse its different properties, change it based on your need, monitor its usage, run your queries in Query Editor as part of the Azure Portal (in preview right now) etc. as shown in the figure below:
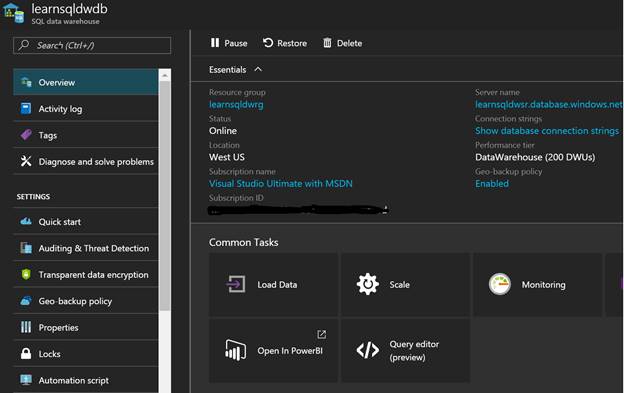
Query Editor
As mentioned earlier, you can go to the Scale tab to scale your database up or down using the provided slider, as shown in the figure below, based on your need:
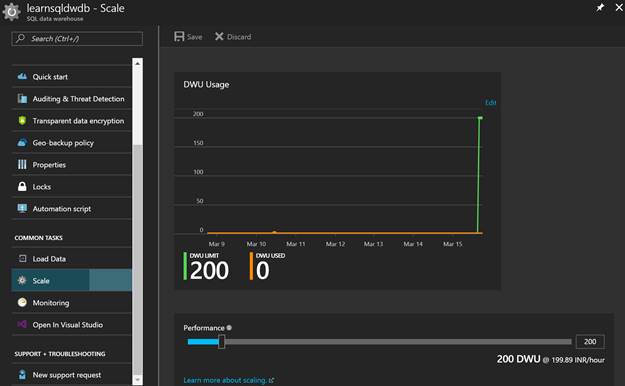
Scale up or down
Azure SQL Data Warehouse is a secured and protected environment; to access it from outside Azure, you need to first add the IP address of the machine, in the Firewall setting from where you are trying to access it. To do that, you need to go to the Firewall tab for the SQL Server and add IP or IP ranges from where you are intending to access databases hosted on this specific SQL Server:
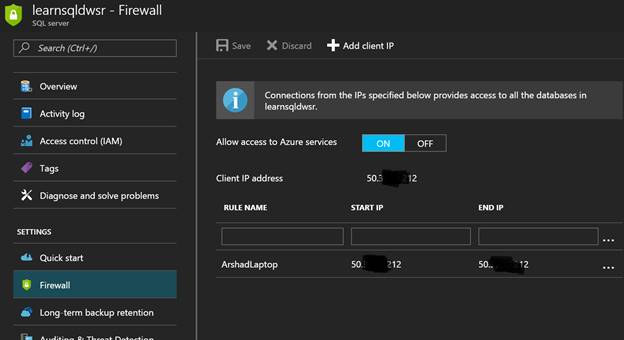
SQL Server Firewall
If you try accessing Azure SQL Server from SQL Server Management Studio (or any client tools) without adding that specific client IP address, it will fail with the following message:
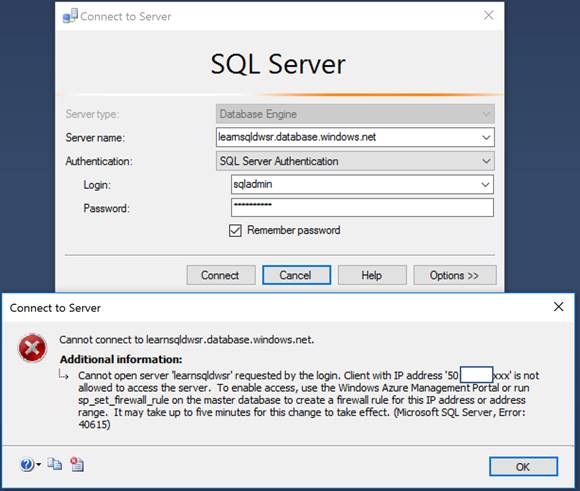
Connect to Server
Once you have added your client IP (specific IP address or as part of an IP range) to the allowed IP list in the SQL Server Firewall, you can connect and browse your SQL Data Warehouse database from any client tool on that machine. For example, you can see Object Browser in SQL Server Management Studio connected to the database, as shown in figure below:
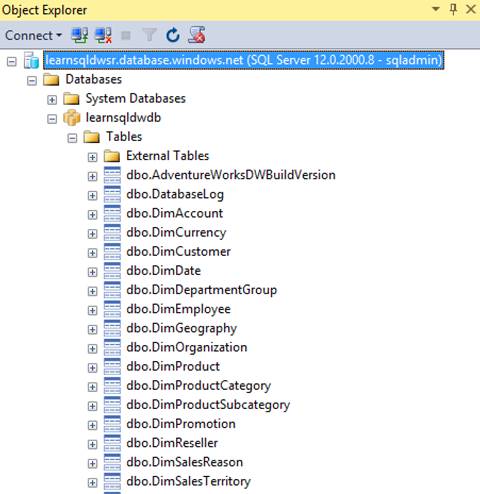
Object Explorer
If you are a developer and use Visual Studio for your development, you can use SQL Server Object Explorer in Visual Studio to connect, browse and work with SQL Data Warehouse database, as shown below:
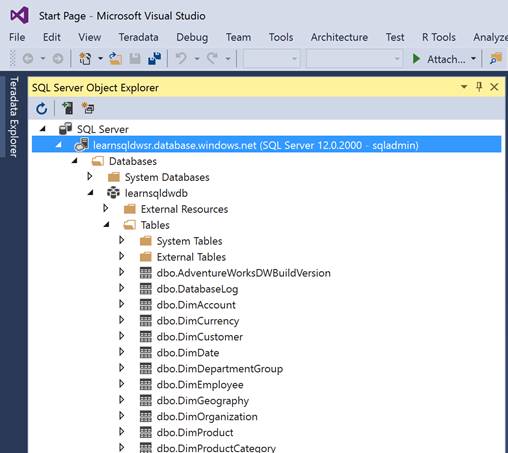
Microsoft Visual Studio
Conclusion
In this article I talked about the different types of tables we create in SQL Data Warehouse, how they impact performance and best practices around them. We also saw how to get started with creating our first SQL Data Warehouse database.
In the next article of the series, we will look at hash distributed and round-robin tables in more detail, how to create them, how query execution is impacted based on this decision etc.
Resources
Getting Started with Azure SQL Data Warehouse – Part 1
Getting Started with Azure SQL Data Warehouse – Part 2
Design for Big Data with Microsoft Azure SQL Data Warehouse