


Introduction
Column Store Index, which improves performance of data warehouse queries several folds, was first introduced in SQL Server 2012. Though it had several limitations, now SQL Server 2014 enhances the columnstore index and overcomes several of the earlier limitations. In this article, I am going to discuss how you can get started using the enhanced columnstore index feature in SQL Server 2014 and do some performance tests.
If you are new to columnstore index, you can refer my earlier articles on the topic to understand it better.
- Understanding New Columnstore Index of SQL Server 2012
- Getting Started with the New Columnstore Index of SQL Server 2012
- New Enhanced Columnstore Index in SQL Server 2014 – Part 1
- Getting Started with Columnstore Index in SQL Server 2014 – Part 1
Getting Started with Clustered Columnstore Index
In this demonstration, I am going to create three tables with the following index specifications, with same number of records, to demonstrate different performance behaviors with different types of indexes:
- Table with clustered index (row-store) and non-clustered index (row-store)
- Table with clustered index (row-store) and non-clustered columnstore index
- Table with clustered columnstore index
The script below creates three tables with no index (heap).
USE AdventureWorks2012
--Table with Row Store index clustered index and Row Store non-clustered index
CREATE TABLE SalesOrderDetailWithRowStoreClusteredIndexAndRowStoreNonClusteredIndex(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] IDENTITY(1,1) NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [money],
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL
) ON [PRIMARY]
GO
--Table with Row Store clustered index and non-clustered Column Store index
CREATE TABLE SalesOrderDetailWithRowStoreClusteredIndexAndNonClusteredColumnStoreIndex(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] IDENTITY(1,1) NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [money],
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL
) ON [PRIMARY]
GO
--Table with Column Store Clustered index
CREATE TABLE SalesOrderDetailWithClusteredColumnStoreIndex(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] IDENTITY(1,1) NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [money],
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL
) ON [PRIMARY]
GO
The script below loads close to 10 million rows into the above created three tables with no index (heap) from the AdventureWorks.Sales.SalesOrderDetail.
USE AdventureWorks2012
--Load data to these tables
INSERT INTO SalesOrderDetailWithRowStoreClusteredIndexAndRowStoreNonClusteredIndex (SalesOrderID,
CarrierTrackingNumber,
OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount, LineTotal, rowguid,
ModifiedDate)
SELECT SalesOrderID, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount,
LineTotal, rowguid, ModifiedDate FROM [AdventureWorks2012].Sales.[SalesOrderDetail]
GO 85
INSERT INTO SalesOrderDetailWithRowStoreClusteredIndexAndNonClusteredColumnStoreIndex
(SalesOrderID, CarrierTrackingNumber,
OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount, LineTotal, rowguid,
ModifiedDate)
SELECT SalesOrderID, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount,
LineTotal, rowguid, ModifiedDate FROM [AdventureWorks2012].Sales.[SalesOrderDetail]
GO 85
INSERT INTO SalesOrderDetailWithClusteredColumnStoreIndex (SalesOrderID, CarrierTrackingNumber,
OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount, LineTotal, rowguid,
ModifiedDate)
SELECT SalesOrderID, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount,
LineTotal, rowguid, ModifiedDate FROM [AdventureWorks2012].Sales.[SalesOrderDetail]
GO 85
Now let me create the clustered index (row-store) and one non-clustered index (row-store) on the first table.
USE AdventureWorks2012
--Creating Indexes - Row Store index clustered index and Row Store non-clustered index
CREATE CLUSTERED INDEX
[CIRS_SalesOrderDetailWithRowStoreClusteredIndexAndRowStoreNonClusteredIndex_SalesOrderID_SalesOrderDetailID]
ON SalesOrderDetailWithRowStoreClusteredIndexAndRowStoreNonClusteredIndex
(SalesOrderID, SalesOrderDetailID)
GO
CREATE NONCLUSTERED INDEX
[NCRS_SalesOrderDetailWithRowStoreClusteredIndexAndRowStoreNonClusteredIndex_ProductID_LineTotal]
ON SalesOrderDetailWithRowStoreClusteredIndexAndRowStoreNonClusteredIndex
(ProductID, LineTotal)
GO
Next, I create a clustered index (row-store) and a non-clustered columnstore index on the second table.
USE AdventureWorks2012
--Creating Indexes - Row Store clustered index and non-clustered Column Store index
CREATE CLUSTERED INDEX
[CIRS_SalesOrderDetailWithRowStoreClusteredIndexAndNonClusteredColumnStoreIndex_SalesOrderID_SalesOrderDetailID]
ON SalesOrderDetailWithRowStoreClusteredIndexAndNonClusteredColumnStoreIndex
(SalesOrderID, SalesOrderDetailID)
GO
CREATE NONCLUSTERED COLUMNSTORE INDEX
[NCCS_SalesOrderDetailWithRowStoreClusteredIndexAndNonClusteredColumnStoreIndex_ProductID_LineTotal]
ON SalesOrderDetailWithRowStoreClusteredIndexAndNonClusteredColumnStoreIndex
(ProductID, LineTotal)
GO
And finally, I create a clustered columnstore index on the third table and no other indexes (please note, a table with clustered columnstore index cannot have any other indexes). For exhaustive detail and explanation on the syntax for creating clustered columnstore index, click here.
USE AdventureWorks2012
--Creating Indexes - Column Store Clustered index
CREATE CLUSTERED COLUMNSTORE INDEX [CICC_SalesOrderDetailWithClusteredColumnStoreIndex]
ON SalesOrderDetailWithClusteredColumnStoreIndex
GO
I have loaded the same number of rows (~10 million) in each of these tables, and this is how you can verify it:
USE AdventureWorks2012
SELECT Count(*) FROM SalesOrderDetailWithRowStoreClusteredIndexAndRowStoreNonClusteredIndex
SELECT Count(*) FROM SalesOrderDetailWithRowStoreClusteredIndexAndNonClusteredColumnStoreIndex
SELECT Count(*) FROM SalesOrderDetailWithClusteredColumnStoreIndex
GO
Now we can run an aggregation query on the columns included in the index as shown below:
USE AdventureWorks2012
SELECT ProductID, SUM(LineTotal) AS 'ProductWiseSale' FROM
SalesOrderDetailWithRowStoreClusteredIndexAndRowStoreNonClusteredIndex
GROUP BY ProductID
ORDER BY ProductID
SELECT ProductID, SUM(LineTotal) AS 'ProductWiseSale' FROM
SalesOrderDetailWithRowStoreClusteredIndexAndNonClusteredColumnStoreIndex
GROUP BY ProductID
ORDER BY ProductID
SELECT ProductID, SUM(LineTotal) AS 'ProductWiseSale' FROM
SalesOrderDetailWithClusteredColumnStoreIndex
GROUP BY ProductID
ORDER BY ProductID
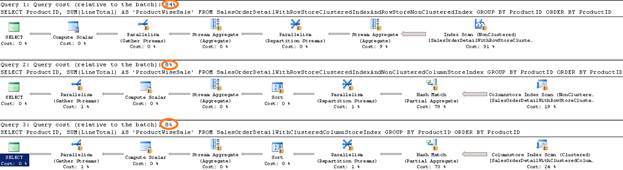
If we look at the execution plan of the above three queries, the first query (which involves a table with clustered index (row-store) and non-clustered index (row-store)) has 84% relative cost in the batch with respect to other two queries. The second query (which involves a table with clustered index (row-store) and a non-clustered columnstore index) and the third query (which involves a table with clustered columnstore index) have 8% relative cost for each of these queries:
Now if we look at the IO (Input\Output) statistics of the above three queries this how it looks:
(266 row(s) affected)
Table 'SalesOrderDetailWithRowStoreClusteredIndexAndRowStoreNonClusteredIndex'. Scan count 5,
logical reads 33538, physical reads 0, read-ahead reads 33309, lob logical reads 0, lob
physical reads 0, lob read-ahead reads 0.
(266 row(s) affected)
Table 'SalesOrderDetailWithRowStoreClusteredIndexAndNonClusteredColumnStoreIndex'. Scan count
4, logical reads 790, physical reads 11, read-ahead reads 151, lob logical reads 0, lob
physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob
logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob
logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(266 row(s) affected)
Table 'SalesOrderDetailWithClusteredColumnStoreIndex'. Scan count 4,
logical reads 10398, physical reads 3, read-ahead reads 4128, lob logical reads 0, lob physical reads 0, lob read-
ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob
logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob
logical reads 0, lob physical reads 0, lob read-ahead reads 0.
If we look at the CPU time statistics of the above three queries this how it looks:
(266 row(s) affected)
SQL Server Execution Times:
CPU time = 4578 ms, elapsed time = 15008 ms.
(266 row(s) affected)
SQL Server Execution Times:
CPU time = 328 ms, elapsed time = 1103 ms.
(266 row(s) affected)
SQL Server Execution Times:
CPU time = 421 ms, elapsed time = 806 ms.
The conclusion here is, the first query, which uses only row-store (B-Tree) indexes, is 10x slower than the queries that use columnstore indexes (irrespective of whether it’s non-clustered columnstore index or clustered columnstore index).
Now if you are wondering what is the difference between non-clustered columnstore index and clustered columnstore indexes, let’s run these queries and analyze it further:
USE AdventureWorks2012
SELECT ProductID, SUM(OrderQty) AS OrderQty, SUM(UnitPriceDiscount) AS UnitPriceDiscount, SUM(LineTotal) AS 'ProductWiseSale' FROM
SalesOrderDetailWithRowStoreClusteredIndexAndRowStoreNonClusteredIndex
GROUP BY ProductID
ORDER BY ProductID
SELECT ProductID, SUM(OrderQty) AS OrderQty, SUM(UnitPriceDiscount) AS UnitPriceDiscount,
SUM(LineTotal) AS 'ProductWiseSale' FROM
SalesOrderDetailWithRowStoreClusteredIndexAndNonClusteredColumnStoreIndex
GROUP BY ProductID
ORDER BY ProductID
SELECT ProductID, SUM(OrderQty) AS OrderQty, SUM(UnitPriceDiscount) AS UnitPriceDiscount,
SUM(LineTotal) AS 'ProductWiseSale' FROM
SalesOrderDetailWithClusteredColumnStoreIndex
GROUP BY ProductID
ORDER BY ProductID
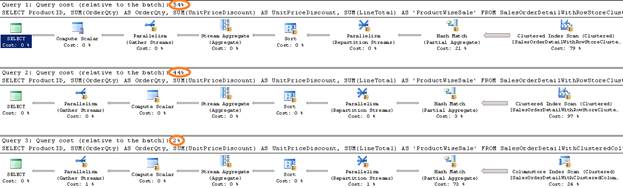
If we look at the execution plan of the above three queries, the first query (which has a table with clustered index (row-store) and non-clustered index (row-store)) has 54% relative cost in the batch with respect to the other two queries. The second query (which has a table with clustered index (row-store) and non-clustered columnstore index) has 44% relative cost in the batch with respect to the other two queries and third query (which has a table with clustered columnstore index) has 24% relative cost in the batch with respect to the other two queries.
Now the question is why is this so? Well, even though the first query has a non-clustered index it’s not being used because the query has several other aggregations based on columns that are not part of the index and hence Optimizer chose to do a Cluster Index Scan instead of Index Scan.
The case is the same with the second query, even though the second query has non-clustered columnstore index it’s not being used because the query has several other aggregations based on columns that are not part of the non-clustered columnstore index and hence Optimizer chose to do a Cluster Index Scan instead of a Columnstore Index Scan.
Now if you look at the IO statistics, you’ll notice the last query has more than 10 times better performance than the first and second query:
(266 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob
logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob
logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'SalesOrderDetailWithRowStoreClusteredIndexAndRowStoreNonClusteredIndex'. Scan count 5,
logical reads 117635,
physical reads 0, read-ahead reads 116828, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(266 row(s) affected)
Table 'SalesOrderDetailWithRowStoreClusteredIndexAndNonClusteredColumnStoreIndex'. Scan count
5, logical reads 117450, physical reads 0, read-ahead reads 116828, lob logical reads 0, lob
physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob
logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob
logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(266 row(s) affected)
Table 'SalesOrderDetailWithClusteredColumnStoreIndex'. Scan count 4, logical reads 11043, physical reads 9, read-ahead reads 4176, lob logical reads 0, lob physical reads 0, lob read-
ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob
logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob
logical reads 0, lob physical reads 0, lob read-ahead reads 0.
If you look at the time statistics, you can notice the last query again has more than 15 times better performance than first and second query:
(266 row(s) affected)
SQL Server Execution Times:
CPU time = 6453 ms, elapsed time = 49832 ms.
(266 row(s) affected)
SQL Server Execution Times:
CPU time = 4874 ms, elapsed time = 38386 ms.
(266 row(s) affected)
SQL Server Execution Times:
CPU time = 689 ms, elapsed time = 2424 ms.
As I said before for columnstore index, data gets stored in row groups and then to column segments; you can use the below queries to find out information about them along with the number of rows\values stored and disk size:
USE AdventureWorks2012
SELECT object_name(object_id) as ObjectName, * FROM sys.column_store_row_groups
ORDER BY object_id, row_group_id
SELECT object_name(p.object_id) AS ObjectName, C.column_id, C.segment_id , C.partition_id,
sum(C.on_disk_size) AS on_disk_size, SUM(C.row_count) AS row_count
FROM sys.column_store_segments C
INNER JOIN sys.partitions p
ON C.partition_id=p.partition_id
GROUP BY P.object_id, C.partition_id, C.column_id, C.segment_id
ORDER BY P.object_id, C.partition_id, C.column_id, C.segment_id
Conclusion
In this article, I showed how to get started with column store index and demonstrated some performance tests for evaluating different options.
Resources
Enhancements to SQL Server Column Stores
Understanding new Column Store Index of SQL Server 2012
Getting Started with the New Column Store Index of SQL Server 2012