


In this second article of the series, we will discuss some of the issues that we laid down last time. I received an email from another beta tester who complained about some features that did not exist in SoRAC. He said it is just live data. I asked him “And what do you think a DBA does most of the time? Keep fixing problems?” Certainly not! They want to monitor their database and what better way to monitor than watching it live!
Although we will not delve into the “good to have” or “nice to have utilities” here, you can send feedback to Quest Software. I also put up a simple AVI file on my Oracle blog ; download it to see it in action here. While doing the recording, I did not mouse over all of moving parts as it caused the recording to freeze. However, if you move your mouse over your own SoRAC when you run it, you will see full detailed information of the activity.
It’s all about those ringing Alarms…
…and drilldowns . We will check out some typical alarms. Notice that only useful and crucial alarms have been put on high priority; low priority alarms have been adjusted with a “low load filter,” so that you aren’t alarmed all the time.
If there is little activity in your cluster, the alarm will not be triggered. Since the default value for low load is “(Total Logical Reads/sec) = 500”, if there is no activity below this value then the alarm will not be fired.
Oracle Aggregated Alarms
SoRAC treats an Oracle RAC as a single database and aggregates all of the Spotlight on Oracle (SoO) metrics (to create cluster wide metrics) to set alarm thresholds, which in turn are scaled as per the load on each node.
For instance, the “enqueue wait percentage” for a single node would be calculated this way:
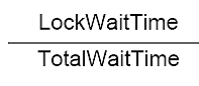
And SoRAC aggregates it as follows:
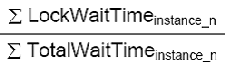
You get the idea. If, for instance, node2 complains of being blocked by node1, then the alarm condition is not really impacting your Oracle RAC instance as a whole. The whole idea of the aggregated metrics is not to start hyperventilating if one node happens to have contention.
As in you see in below scenario, the alarm is raised even though there is no problem on RAC as a whole. Here you can see that instance 1 created a lock and instance 2 is locked and must wait. We do not know why the second instance is blocked.
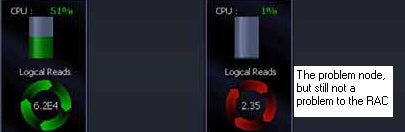
This is a perfect example of a total RAC cluster centric metrics that no other diagnostic tool provides. You can get full details on the session if you click on a session with the sub drilldown.
![]()
If lock contention becomes sufficiently widespread, Spotlight on RAC will raise a cluster-wide alarm; otherwise, only those instance suffering from lock contention will show an alarm. The same logic is used for other potential problems such as latches, buffer busy, poor IO response times, etc.
Balance Alarm
An ideally load balanced cluster is crucial for the functioning of a healthy and productive Oracle RAC. Many have faced defeat and shame when moving from a single node to a clustered situation, in the hope of saving face.
As Quest’s Technical Manual states:
“SoRAC calculates balance by recording a user-definable metric of load over time on each instance (the default is Logical Reads, but the user can switch this to CPU usage or Physical Writes via the Spotlight on RAC Options), and calculating the relative balance of load across the cluster. This balance is represented as a percentage where 100% represents perfectly balanced (each instance in the cluster is doing the same amount of work) and 0% represents completely imbalanced (one instance in the cluster is doing all the work).
Because we expect that there will be variations in load between instances within the cluster in the normal course of events, we use a statistical technique to determine if the variation in load that we observe could be simply due to random fluctuations. The statistical technique involved is a nonparametric Analysis of Variance (ANOVA). The non-parametric ANOVA provides us with the probability that the imbalance could be due to random fluctuations. If that probability is less than 5% (eg one chance in twenty) then we fire the imbalance alarm. “
The idea is to tune SoRAC to aviod alarms that do not really impact your RAC as a whole. We need a tool that does not throw an alarm just because a single SQL query (which happens to be a DSS query , runs on one node, bringing it down to its knees for a few seconds) or any other long term minor issues that do not impact our RAC.
Here, for instance a typical single node is put under stress:
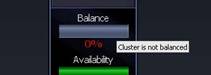
By clicking on the balance drilldown, you get a graph like this and can see for yourself which node has high logical reads.
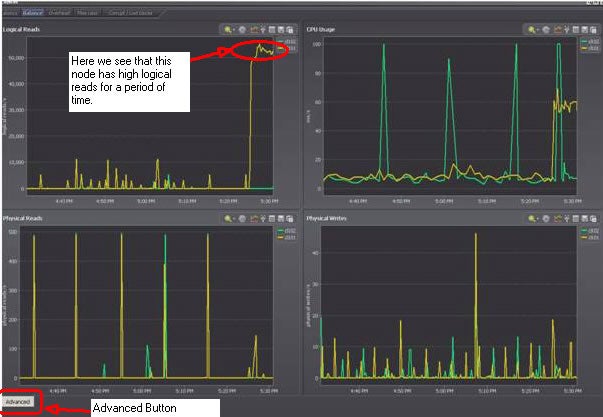
Clicking on the advanced button, you see how these statistical calculations work.
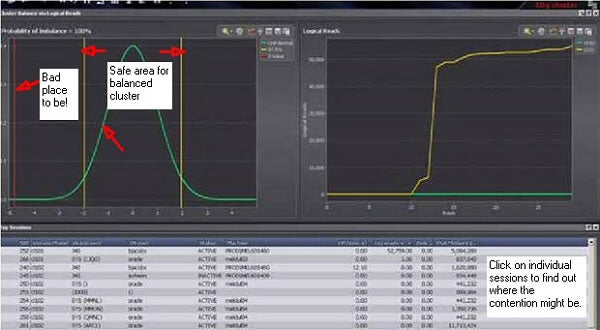
Again quoting theTechnical Manual:
“The green bell curve on the left shows the expected distribution of the balance metric, while the yellow lines represent the 95% confidence limit into which we would expect a balanced cluster metric to fall. The red-line indicating the calculated Z-statistic is outside the 95% “confidence” band, and therefore we can state with a high degree of confidence that the cluster is not balanced. The bell curve will be shown for a two instance cluster. For clusters greater than two instances, the statistical calculation is different, and a chi-squared distribution is shown.
The graph on the right shows the ordered sets of logical reads (that is, the x-axis is by rank value, rather than time, so both lines are always increasing). This is the raw data on which the balance calculation is based. “
Conclusion
In the next and the final series of this series, we will discuss in detail the other Alarms such as Cluster Latency and Overhead Alarms, Global Cache Alarms and ASM Alarms. I previously wanted to dedicate it all in a two article series but I feel that a good introduction to a good monitoring tool will persuade users to test the tool to its limit and understand and appreciate the intelligent mechanism behind it.