


In the concluding part of this series, we will discuss the
cluster latency and overhead alarms, the Global cache alarms and the ASM
alarms.
I am beginning to get emails from people who are attempting
to install RAC on their ESX servers for production servers. There, I suggest
that they get on with tools like SoRAC and even benchmarking tools like Swingbench to evenly
generate the load and make that database sweat!
Yes, you guessed it, we will get on to performance testing
now!
Hear those alarm bells…
The challenge of managing a RAC cluster comes with great
responsibility. Fortunately, we have SoRAC fitted with alarms to warn us about
the problems in advance.
Cluster Latency and Overhead Alarms (CLA and COA)
Cluster latency and overhead alarms are primarily related to
the high speed interconnect. When comparing a single Oracle instance against a
RAC, we see that in a single instance when a user requests data in the form of
a data block, it is first looked at on the “conveyer belt” (buffer with LRU and MRU),
as I will call it here. It is checked in the buffer and if it is not found
there, Oracle retrieves the data block directly from the disk, thus causing a
disk I/O. Not a good thing as you would expect to tune your database to have
the data block in the buffer. Whereas, in a RAC cluster, a session that
requests information (data block) has to request the block from other
instance(s) within the RAC. So actually it has already looked for the block in
its own buffer and since the copy did not exist it goes ahead and requests the
copy of the block from the other clustered instances via the interconnect (your
HSI cable, a 1G or even a 10G cable). Now this block is transferred to the
requesting instance from its buffer; if there is no available block for the
requesting instance, it has to go to the disk to get that block.
All this requesting, transferring and waiting leads to what
is called a “cluster overhead” and as the technical manual says:
“Cluster Overhead is
defined as the amount of time spent waiting for cluster related activities as a
percentage of the total time spent waiting for all activities. If this
percentage exceeds a threshold of 5%, and assuming there is significant work
being done by the cluster, than an overhead alarm is raised. If this percentage
exceeds a threshold of 5%, and assuming there is significant work being done by
the cluster, then an overhead alarm is raised.The cluster latency is
defined as the average elapsed time from when a requesting instance requests a
block of data to the time when the requesting instance receives the block. If
the average time exceeds 5 milliseconds per block, then a latency alarm is
fired. “
The following print screen shows how both Latency and
Overhead issues are rather prominent.
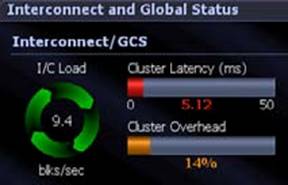
Moreover, normally both of these alarms are fired at the same
time, as high latency is something that you see rather often during a cluster
overhead. These two alarms can fire in the following scenarios:
-
Even if cluster latency is low, an excessive amount of
inter-instance block transfer can cause the cluster overhead to be high. This
might occur if there are “hot” blocks in an application that are constantly
being transferred between instances. -
Cluster latency may be high and still the cluster overhead
bearable as the application has no issues since it finds its blocks on the
local instance. (There is no need to go ahead and fetch it from other
instances, a situation that is typical for a partitioned scenario where a
typical OLTP/DSS database ends up finding its partitioned data on its own
instance).
Upon clicking on the Latency alarm, you can go to the drilldown,
which will display a lot of information regarding the latency issues:

The top left graph shows the overall cluster latency: the
large spike on the right of the graph, when averaged over time, has resulted in
the latency alarm being fired. Note that this graph is only available for
Oracle 10g clusters.
The ping graph shows the time required to transfer a packet
across the HSI (High Speed Interconnect) cable.
All other graphs are a mere breakdown of the latency
components such as “Total Latency,” “Prepare Time,” “Prepare Latency” and
“Transfer Latency,” all rather self-explanatory.
The same thing is seen when we click on the Overhead alarm,
so see the drilldowns displaying a breakdown of the overhead issues: “The
Cluster Overhead graph compares waits due to the RAC interconnect to non-RAC
waits. The recent data shows the RAC waits as a significant percentage of the
overall waits, resulting in the Overhead alarm being fired.“

As you can see on the right, all the color coding says it all.
Global Cache Alarm (GCA)
GCA is further split into the Cache Miss Rate alarm, the Corrupt
Blocks alarm and the Lost Blocks alarm. So what is a cache miss? When a user
requests a data block, the block is cached in the SGA for re-use by other
sessions until such time as the block is not used and the space is required for
other data. A "cache miss" occurs when a data block requested
by the user session is not found in the local SGA, and the block has to be
obtained from a remote instance, or read from disk.
The Cache Miss Rate metric indicates the percentage
of such requests that cannot be satisfied from the local cache, and it directly
affects the overall performance of the cluster. When it exceeds a threshold, a
Global Cache Local Miss Rate alarm is fired. Possible causes of this
alarm are:
-
Hot Blocks (A hot block is the most wanted block; think of certain
queries in your mission critical application which are good candidates for top
10 queries) -
Inappropriately sized local cache (If your local cache does not
have the data, the global cache will be requested).
Check out the print screen:

The Miss Type graph gives a breakdown of the misses for
Current Block requests (for an Update operation) or for Consistent Block requests
(for a Read operation). The other three graphs delve in further details such
as the total misses, current blocks misses and consistent blocks misses.
Now it is a totally different story with corrupt blocks.
Yes, we do have them too, don’t we? SoRAC raises separate alarms for corrupt
and lost blocks. As the manual states,
“The Corrupt Blocks alarm
is raised when the number of corrupt blocks exceeds a threshold as a proportion
of total global cache consistent read requests. The Lost Blocks
alarm is similar, but is based on the number of lost blocks. Possible causes
of these alarms are:
- The cluster interconnect (which I sometimes call HSI) is
overloaded by excessive number of block.- Checksum processes have been disabled and can no longer
identify corrupted blocks.”
Check out this print screen:

As you can see, there are blocks lost (top left).
ASM Alarms
Well, we know by now what ASM is. And yes, we do have alarms
related to ASM as well. This print screen shows a total I/O activity on an ASM
instance.

SoRAC can raise an ASM Service Time alarm when the
average time taken to perform a read on the ASM instance has exceeded a
specified threshold value. This indicates that the ASM subsystem is performing
poorly. “Service time represents the response time of a disk plus any wait
time experienced during disk operations.”
As you can see clearly below, the two graphs show I/O
throughput and service time overhead.

“ASM service time alarms will
typically be associated with alarms for the service time of the shared disk
subsystem as a whole. However, because ASM disk groups can be shared across
multiple RAC clusters and because a cluster may comprise both ASM and non-ASM
storage, it is possible that this alarm might fire independently of the normal
disk alarms.”
Conclusion:
In this last SoRAC article, we have seen that we are using a highly
intelligent tool, which displays all of the information graphically. Needless
to say, it is indeed a very handy tool for DBAs. So, what are you waiting for,
go ahead and try it out!