


Synopsis. Oracle 10g Release 1 added a new and powerful scheduling tool – aptly named the Scheduler – that significantly augments an Oracle DBA’s abilities to schedule and control just about any type of frequently repeating task from within an Oracle 10g database. The final article in this series illustrates how an Oracle DBA can use the new Job Chain capabilities of the Scheduler in Oracle 10g Release 2 (10gR2) to schedule and trigger multiple interrelated and dependent tasks based upon specific yet complex sets of processing rules.
One of the last projects I worked on as a software developer before I became an Oracle DBA was to implement a complex upgrade to several stored procedures within my client’s DB2 database so that a new set of accounting rules could be applied to their commodities management applications. During the several months I spent revamping, testing, and implementing the revised DB2 stored procedures, I became reacquainted with an old friend: MVS/XA Job Control Language, affectionately known to mainframers as JCL.
One of my favorite aspects of JCL is its flexibility and capacity to process complex sets of business rules as a series of steps within a batch job. These steps can interrogate various business states – the arrival of a file; the existence of a prior version of a file; and, perhaps most importantly, the success or failure of prior steps that were executed within that same batch job or even as a part of another batch job. These capabilities mean that a developer has exceptional power to handle even unexpected failures during a batch job’s execution.
When I transitioned to my current Oracle DBA role, I was quickly reminded of how far behind the UNIX, Linux, and Microsoft Windows operating systems were in regards to scheduling mechanisms when compared to mainframe systems. The schedulers that were available tended to be primitive, relatively inflexible, and based either on the CRON or AT operating system commands. Indeed, many of my clients had resorted to purchasing third-party scheduling systems such as CA’s UniCenter tool to handle complex batch processing tasks.
Job Chains to the Rescue
The good news is that Oracle 10gR2 has strengthened the Oracle Scheduler so that it can handle complex batch scheduling with the addition of a new Scheduler object called the job chain. Each job chain is comprised of one or more chain steps, and the relationships between the chain steps are managed by chain rules.
For a practical demonstration of the power of the job chain, I will use the following scenario to satisfy one of the requirements I mentioned in the previous article in this series:
- I need to detect the arrival of a new vendor-supplied external file that contains accounting information (in this scenario, employee paychecks). The file is supposed to arrive twice a month before the bimonthly payroll cycle begins; however, during recent payroll processing cycles, this file has arrived unexpectedly late or early.
- Once the file arrives, it must be validated based on specific business rules. If any of these validations fail, all further processing must halt, and a notification needs to be sent to the DBA that the job has failed.
- Once the file is validated, its contents must be loaded into a database table.
- If any DML errors occur during the load – for instance, if a column’s size is exceeded, or if a check constraint is violated – then the job needs to notify the appropriate accounting personnel.
- Once the file’s contents have been loaded, I need to notify the appropriate business unit of its successful processing, and send along a summary of how many records were processed.
- If there are any post-loading error conditions – for example, if the employee’s Social Security contributions for the year have exceeded the mandated maximum – then I need to notify the appropriate accounting personnel as well.
I have summarized these business rules in the following flowchart.
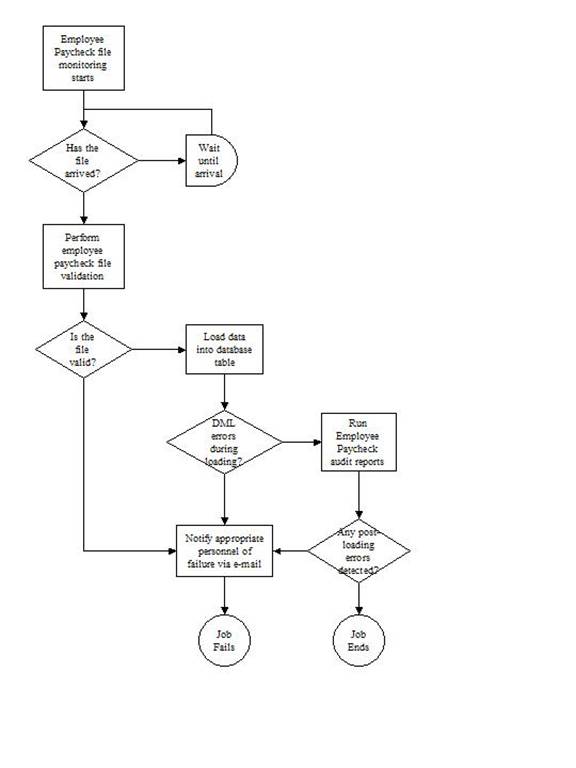
Figure 1. Bimonthly Employee Payroll Check External File Processing Flow
To implement these requirements, I first need to build the infrastructure to handle the incoming payroll checks. I will start by creating an external table, HR.XT_EMPLOYEE_PAYROLL_CHECKS, that describes the layout of the incoming file. I will use this external table for two purposes: to run validation queries against the incoming data before loading it, and to read from the file during the loading process. Listing 2.1 shows the code I used to create the external table, as well as the creation of the DIRECTORY object that Oracle needs to locate the flat file.
I will next create a standard database table, HR.EMPLOYEE_PAYROLL_CHECKS, that will be used to store each payroll check that passes validation. The code in Listing 2.2 shows how to create this table and its dependent indexes and constraints.
Finally, I will create a package named HR.PAYROLL_PROCESSING that encapsulates all business logic for processing of employee paychecks. I will call this package’s functions and procedures within my job chain’s steps to validate the incoming file, load its data into the database, and perform post-loading validation. Note that I am also using DBMS_ERRLOG.CREATE_ERROR_LOG to create a DML error logging table that will trap any DML errors that might occur when loading the HR.EMPLOYEE_PAYROLL_CHECKS table. This is a brand-new feature in Oracle 10gR2 that makes it simple to capture unexpected data issues when inserting, updating or deleting rows. Listing 2.3 shows the code to create the DML error logging table, package specification, and package body.
Chain Steps and Chain Rules
Now that the infrastructure is completed, I will turn my attention to implementing the job chain via the two job chain components, chain steps and chain rules.
As its name suggests, a chain step groups together similar business processes into a larger logical unit of work. As each chain step completes its processing, Oracle records the status of the step in a special queue, SCHEDULER$_QUEUE. Scheduler jobs, job chains or even chain steps within the same job chain can interrogate this queue so that other dependent business processes can be triggered.
Chain rules, on the other hand, define when a chain step should begin its processing, which chain step(s) should commence upon success of a specific chain step, and what chain step(s) should commence upon failure of a specific chain step.
Starting a Chain Based on an Event
Like the standard, public SYS.AQ_EVENT and SCHEDULER$_QUEUE event queues, I also have the capability to create a private event queue reserved for publishing (or enqueueing) a specific message – for example, the arrival of the bimonthly payroll checks file. And just like any event queue, a private event queue can be read by other Scheduler objects and thus used to trigger other Scheduler tasks.
Via the code in Listing 2.4, I will establish a new queue, SYS.FILE_ARRIVAL_EVENT_Q, into which I will eventually queue a message when the new Employee Paycheck file has arrived. I will also create a new agent, AGT_FILE_EVENT_MONITOR, that is responsible for watching the new queue for the arrival of the new file. Note that I have granted specific privileges to the HR user account so that it can both post a message to the file arrival event queue and read from the queue to determine if the file has arrived and if the job chain can commence.
Creating a Job Chain
Next, I will tackle the creation of the Job Chain and its components. First, I will create a new job chain Scheduler object, BIMONTHLY_PAYROLL_PROCESSING, that is owned by the HR schema via a call to the DBMS_SCHEDULER.CREATE_CHAIN procedure. Once that is in place, I will then create job chain step Scheduler objects. Note that the first step in the chain, PAYROLL_VALIDATION, is defined with procedure DBMS_SCHEDULER.DEFINE_CHAIN_EVENT_STEP. This procedure relies upon a special Scheduler schedule object, HR.MONITOR_PAYCHECK_ARRIVAL, that will watch for the arrival of the file and then allow the job chain to begin its processing.
The remaining job chain steps will be defined via the DBMS_SCHEDULER.DEFINE_CHAIN_STEP procedure. These chain steps will then call corresponding Scheduler program objects to handle various phases of the payroll checks file processing. Once all the chain steps are created, I will build job chain rule Scheduler objects that determine what should happen upon success or failure of each job chain step using the DBMS_SCHEDULER.DEFINE_CHAIN_RULE procedure.
Listing 2.5 shows the code required to create the job chain, chain steps, and chain step rules, as well as the three Scheduler program objects that process the Employee Payroll checks file.
Starting a Chain via a Scheduled Job
I will now create the previously mentioned HR.MONITOR_PAYCHECK_ARRIVAL Scheduler schedule object. This object will monitor the SYS.FILE_ARRIVAL_EVENT_Q via the SYS.AGT_FILE_ARRIVAL_MONITOR agent and, when the requested external file arrives, this schedule will signal the job chain to start its processing scheme. Note that I could use the file arrival event queue to register the arrival of many other external files in any schema, but this schedule object will activate itself only when the Employee Payroll Checks file arrives.
Since all of the Job Chain pieces are in place, I will activate the chain via a call to the DBMS_SCHEDULER.ENABLE procedure. Finally, since every job chain must be started by a call from a Scheduler job object, I will create a new job, HR.CHN_START_PAYROLL_PROCESSING, that will start to run a day before the anticipated arrival of the Employee Payroll Checks file and will continue to run until either (a) the file arrives, or (b) 48-hours have passed. If the file never arrives, the job will simply never run. I have included the code to complete the job chain setup in Listing 2.6.
Proof of Concept: Starting the Job Chain upon File Arrival
All the pieces are in place, so it is time for an actual demonstration. Via the code in Listing 2.7 I will initiate the HR.CHN_START_PAYROLL_PROCESSING outside of its normal schedule by invoking the DBMS_SCHEDULER.RUN_JOB procedure. Even though the job chain is now started, it will continue to wait until either (a) its first job chain step detects the arrival of the employee payroll checks file, or (b) the job itself runs out of time to execute (based on its defined 48-hour schedule).
First, I will place a test copy of the Employee Payroll Checks file into the appropriate directory, and then I will run the code in the anonymous PL/SQL block in Listing 2.7. This block of code queues a message in the SYS.FILE_ARRIVAL_EVENT_Q queue to simulate the file’s arrival. The event will be detected by the PAYROLL_VALIDATION job chain step, and the job will then commence its processing in earnest.
Obviously, unit testing a job chain with greater complexity than this example could easily become a labor-intensive nightmare. Fortunately, the Scheduler provides another unit-testing option: DBMS_SCHEDULER.RUN_CHAIN. This procedure lets me specify one or more job chain steps to be started, and the RUN_CHAIN will start the job chain steps and allow the job to continue to its conclusion. Even better, this procedure is overloaded so that I can also specify one or more steps to start, but also include their current state (e.g. FAILED, SUCCEEDED) so that I can easily test out chain step rule processing. I have provided an example of both invocations of this procedure in Listing 2.8.
As the flowchart in Figure 1 shows, there are at least three points in this job chain’s processing flow at which a failure could occur and trigger an expected alternative to successful job completion. The sample data I have included to demonstrate these examples contain seven rows that have unacceptable values for the HR.EMPLOYEE_PAYROLL_CHECKS.STATUS_IND column. These rows will be logged to the HR.PAYROLL_PROCESSING_ERRORS DML error logging table, and this triggers a failure of the job chain step LOAD_PAYROLL_CHECKS.
When a Scheduler job chain is initiated, the Oracle Scheduler actually creates a one-time-only job whose job name corresponds to that of each chain step. These jobs can be easily tracked either via the Enterprise Manager Database Control Scheduler, or simply by running a few queries against DBA_SCHEDULER_JOB_LOG and DBA_SCHEDULER_JOB_RUN_DETAILS. I have included a few sample reports from my unit testing results in Listing 2.9.
Viewing Job Chain Metadata
Four new data dictionary views describe the Scheduler’s new job chain components:
- DBA_SCHEDULER_CHAINS shows all current job chains.
- DBA_SCHEDULER_CHAIN_STEPS shows the corresponding job chain steps.
- DBA_SCHEDULER_CHAIN_RULES shows the corresponding chain step rules.
- Finally, DBA_SCHEDULER_RUNNING_CHAINS shows the current status of any job chains that are running at this moment.
Listing 2.10 shows several queries that can be used to view the contents of these new views.
Conclusion
Oracle 10gR2 has made significant improvements to the flexibility and versatility of the Oracle Scheduler with new capabilities to combine multiple independent schedules into one coherent schedule, trigger a job based on the status of a queued event, and control and process complex business rules and relationships with job chains, chain steps, and chain rules. These new features raise the bar for intra-database scheduling capabilities to a new height, and demand the serious attention of any Oracle DBA as effective alternatives to operating system-based or third-party scheduling tools.
References and Additional Reading
Even though I have hopefully provided enough technical information in this article to encourage you to explore with these features, I also strongly suggest that you first review the corresponding detailed Oracle documentation before proceeding with any experiments. Actual implementation of these features should commence only after a crystal-clear understanding exists. Please note that I have drawn upon the following Oracle 10gR2 documentation for the deeper technical details of this article:
B14214-01 Oracle Database New Features Guide
B14229-01 Oracle Streams Concepts and Administration
B14231-01 Oracle Database Administrator’s Guide
B14257-01 Oracle Streams Advanced Queuing User’s Guide and Reference
B14258-01 PL/SQL Packages and Types Reference