


As mentioned in a previous article, one of the benefits of being able to examine alternate execution plans derived from an original SQL statement is seeing how Oracle attempts to come up with a different approach. The different approaches can be divided into two areas: the use of hints and the rewriting or restructuring of the original SQL statement.
What does “WHERE A = B” mean?
In many other areas of technology, because of what is drilled into us by language and habit, we’ve become accustomed to seeing expressions or statements of equality written or presented to us as “where some variable = some specific value.” In programming logic, this is especially prevalent and you expect to see tests (in the form of IF-THEN constructs) written as “If variable X equals some value, then do something.”
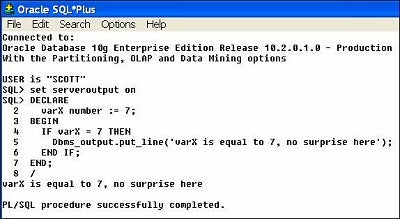
What happens if we reverse the A and B part of the test, that is, test to see if 7 is equal to X?
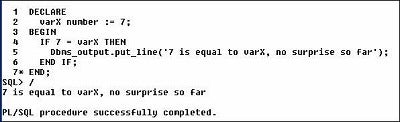
Given that we can switch the order of A and B in the simple example used so far and have both tests work, can we use the same reversal in SQL statements? For example, how many times have you seen WHERE clauses such as “WHERE empno = 7359” or “job = ‘CLERK’” in the SCOTT schema?
SQL> select * from emp where job = ‘CLERK’;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
——- ———- —– —– ——— —– —– ——-
7369 SMITH CLERK 7902 17-DEC-80 800 20
7876 ADAMS CLERK 7788 23-MAY-87 1100 20
7900 JAMES CLERK 7698 03-DEC-81 950 30
7934 MILLER CLERK 7782 23-JAN-82 1300 10
So, now using the reverse order of A and B, that is, WHERE ‘CLERK’ = job, what do we get?
SQL> select * from emp where ‘CLERK’ = job;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
——- ———- —– —– ——— —– —– ——-
7369 SMITH CLERK 7902 17-DEC-80 800 20
7876 ADAMS CLERK 7788 23-MAY-87 1100 20
7900 JAMES CLERK 7698 03-DEC-81 950 30
7934 MILLER CLERK 7782 23-JAN-82 1300 10
Is it surprising that you can reverse the ordering of the predicates? Writing the “value” part first and then comparing it to the column/variable name second goes against how we’ve been taught to write the test part of statements. If you think about this for a moment, given that you’ve coded a SQL statement joining two tables, you’ll realize that you’ve been doing “where B equals A” all along. It’s just been a matter of perspective.
In terms of the output, there is absolutely no difference between the two statements shown below.
SQL> select empno, ename, b.dname
2 from emp a, dept b
3 where a.deptno=b.deptno
4 and ‘CLERK’ = job;
EMPNO ENAME DNAME
——- ———- ———–
7369 SMITH RESEARCH
7876 ADAMS RESEARCH
7900 JAMES SALES
7934 MILLER ACCOUNTING
|
SQL> select empno, ename, b.dname
2 from emp a, dept b
3 where b.deptno=a.deptno
4 and ‘CLERK’ = job;
EMPNO ENAME DNAME
——- ———- ———–
7369 SMITH RESEARCH
7876 ADAMS RESEARCH
7900 JAMES SALES
7934 MILLER ACCOUNTING
|
In the WHERE clause, where the DEPTNO values are being tested/joined, the choice between using a.deptno=b.deptno versus b.deptno=a.deptno is essentially arbitrary. The reverse ordering, so to speak, extends to other functions as well. In the examples below, the substring test works just as well on both sides of the equals sign.
SQL> select empno, ename from emp
2 where substr(job,1,3) = ‘CLE’;
EMPNO ENAME
—– ——
7369 SMITH
7876 ADAMS
7900 JAMES
7934 MILLER
|
SQL> select empno, ename from emp
2 where ‘CLE’ = substr(job,1,3);
EMPNO ENAME
—– ——
7369 SMITH
7876 ADAMS
7900 JAMES
7934 MILLER
|
Now that we’ve confirmed that the left and right sides of an equality test can be switched, the shock value of seeing what intuitively looks odd or wrong in an explain plan (from an alternative scenario as shown in Toad for Oracle’s SQL Optimizer) should be minor. Let’s take a look at a 3-way join. The original SQL is shown below.
Select /*+ INDEX_DESC(U) */
substr(c.email_message_id,1,3) c_client_id,
substr(c.email_message_id,4,2) c_product_id,
substr(c.email_message_id,6,8) c_build_id,
substr(c.email_message_id,14,8) c_email_id,
decode(substr(c.email_message_id,22,1),’a’,1,’d’,4) c_email_format_id,
c.click_date,
c.email_message_id,
f.mail_date,
f.email_address_id,
u.url_id,
c.click_status,
c.rowid ctr_rowid,
f.content_sub_product,
f.build_date,
nvl(f.domain_id, 0) domain_id
from clickthru_stage c,
flight_history f,
tracked_urls u
where c.click_date > sysdate – 7
AND f.build_date > sysdate – 21
AND c.log_id is null
AND c.ricochet_link_id = u.ricochet_link_id
AND u.product_id = substr(c.email_message_id, 4, 2)
AND f.email_message_id = c.email_message_id
AND u.product_id = substr(f.email_message_id, 4, 2)
AND substr(c.email_message_id, 4, 2) = substr(f.email_message_id, 4, 2);
Shown below is the WHERE clause from an alternative scenario.
where 7 > sysdate – c.click_date
AND 21 > sysdate – f.build_date
AND c.log_id is null
AND u.ricochet_link_id = c.ricochet_link_id
AND u.product_id = substr(c.email_message_id, 4, 2)
AND c.email_message_id = f.email_message_id
AND u.product_id = substr(f.email_message_id, 4, 2)
AND substr(c.email_message_id, 4, 2) = substr(f.email_message_id, 4, 2)
AND substr(f.email_message_id, 4, 2) = substr(f.email_message_id, 4, 2)
Note how the numeric values for sysdate versus click_date/build_date are placed on the left hand side. Looking at the code in more detail, we can see that several of the table_alias.column_name comparisons have been reversed as well. In this particular example, the SQL Optimizer did not alter the order of the tables. They stayed as in the original code (clickthru_stage, flight_history and tracked_urls).
A couple of interesting things can be seen when looking at the alternative statements. Not shown in this alternative but in others, the optimizer will add a plus or minus 0 to a numeric comparison. Instead of build_date > sysdate – 21, you may see build_date > sysdate – 21 – 0. Another artifact is appending a blank/empty string to the end of something being substringed, as in
u.product_id = substr(f.email_message_id,4,2)||’’Yet another item, again using the alternative shown here, is the very last line where the same table.column is being compared to itself.
AND substr(f.email_message_id, 4, 2) = substr(f.email_message_id, 4, 2)I would certainly expect the values to be the same, so it seems odd that a test like that would even be considered.
Does the CBO Consider Using a Rule-based Hint?
The Oracle CBO is all about cost, right? Yes, but can you still use rule-based hints? Here is an easy example you can create using the SCOTT schema. I created two tables, named big and small, with 10 million records in the big table and 100 in the small one (BIG is indexed, SMALL is not). The test statements involve the use of IN versus EXISTS. The “Alt #5” transformed statement uses the idea of selecting a smaller population out of a larger one, so instead of using IN, the statement is transformed into one using EXISTS. Seeing that transformation validates what others have suggested as best coding practices. What is of interest here is how the SQL Optimizer tossed in a hint using RULE.
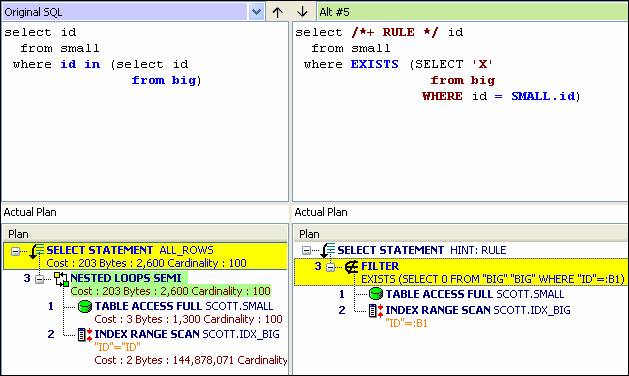
The result of using the RULE hint is that no cost appears in the output. If there is no plan cost, then why does this scenario fall in-between others which do have a computed cost? The “N/A” cost falls between 204 and 3827. Let’s look at these statements the old fashioned way and use AUTOTRACE.
The execution plan for the IN statement is shown below.
SQL> select id from scott.small
2 where exists (select ‘X’ from scott.big where id=scott.small.id);
100 rows selected.
Execution Plan
———————————————————-
Plan hash value: 2310594548
—————————————————————————–
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
—————————————————————————–
| 0 | SELECT STATEMENT | | 100 | 2600 | 203 (0)| 00:00:03 |
| 1 | NESTED LOOPS SEMI | | 100 | 2600 | 203 (0)| 00:00:03 |
| 2 | TABLE ACCESS FULL| SMALL | 100 | 1300 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | IDX_BIG | 11M| 138M| 2 (0)| 00:00:01 |
—————————————————————————–
The plan based on the RULE-based hint (note the plan hash value being smaller by about a factor of 10 than what was computed in the non-RULE version above).
SQL> select /*+ RULE */
2 id from scott.small
3 where exists (select ‘X’ from scott.big where id=scott.small.id);
100 rows selected.
Execution Plan
———————————————————-
Plan hash value: 240595979
————————————–
| Id | Operation | Name |
————————————–
| 0 | SELECT STATEMENT | |
|* 1 | FILTER | |
| 2 | TABLE ACCESS FULL| SMALL |
|* 3 | INDEX RANGE SCAN | IDX_BIG |
————————————–
Is Toad’s SQL Optimizer right or wrong for having used the RULE hint? The answer is that it depends. The RULE hint is still available, but Oracle states, “The RULE hint disables the use of the optimizer. This hint is not supported and should not be used.” If you’re willing to support “known to be on the way out the door for good” features and can still get decent mileage out of them, then why not use it or them?
In Closing
The object lessons of this article and its predecessor include the following:
You don’t have to accept what Oracle (or a third party tool) does in terms of an execution plan recommendation
You can learn interesting coding techniques by examining different SQL statement scenarios
You have a choice (mostly) in determining the order of A and B in comparison tests
Sometimes the simple tools are good enough and quick enough in terms of presenting or explaining options
Clearly, there is a lot going on behind what the optimizer, whether Oracle or third party driven, does or considers when formulating an execution plan. If you see something you don’t understand in a plan, question what it is. You may be paying (in terms of time and performance) for things you can’t really afford.