


The SQL-92 standard unknowingly and without planning introduced the capability to perform full hierarchical data processing with its introduction of the LEFT Outer Join operation. This natural hierarchical processing capability will be explained in this article.
- Database Hierarchical Structure Introduction
- Hierarchical Structure Basics
- Divide and Conquer the Hierarchical Processing Problem
- SQL Hierarchical Data Structure Modeling
- Interpreting Hierarchical Rowsets
- Mapping SQL to Hierarchical Processing at a Conceptual Level
- Querying Multipath Hierarchical Data Structures
- Joining Structures Hierarchically
- Conclusion
Database Hierarchical Structure Introduction
The SQL-92 standard unknowingly and without planning
introduced the capability to perform full hierarchical data processing with its
introduction of the LEFT Outer Join operation. The reasons this powerful capability
has not been used were covered in my previous Database Journal article Ten
Problems with XQuery and the SQL/XML Standard. This natural hierarchical
processing capability will be explained in this article. Current built-in hierarchical
processing support in relational databases has been proprietary and very
limited. Externally added hierarchical processing is not automatic, it is user
driven using functions. Database level hierarchical support for XML and legacy
hierarchical databases like IBM’s IMS and Structured VSAM requires support for
both multiple node types and multiple data occurrences. The support for this
level of hierarchical processing is not practical if performed procedurally and
externally. It must be performed internally and automatically to be practical. This
will also be covered in this article.
Hierarchical Structure Basics
Hierarchical structure principles involve hierarchical data
preservation based on parent and child relationships. This means that parents
can exist without children in the database, but children can not exist without
a parent. If a parent with children is deleted from the database, the related
children and all descendents are removed also. Typically a delete command to a
virtual structure in memory would work the same, but would probably not be
persisted. In the case of retrieving and building the virtual hierarchical
structure in memory by only selecting the nodes desired, the unreferenced nodes
are sliced out of the resulting structure and do not cause removal of lower
level nodes. This is known hierarchically as node promotion and can cause node
collection to automatically occur where a higher level node increases the
number of pathways directly under it. This process changes the structure, but
still preserves its basic structure semantics and integrity. SQL’s SELECT
operation works exactly the same way with its variable SELECT list skipping
around intervening data types. This is known relationally as projection.
Previously, hierarchical structures received a bad
reputation for being fixed and not flexible when relational databases became popular.
In actuality, this did not take fully into account the use of logical hierarchical
structures such as virtual structures mentioned above. Logical hierarchical
structures have unlimited flexibility and even more capability for dynamic
changes to the structure than relational. They can be used in the modeling of
relational tables into a logical hierarchical structure. Flexible logical
hierarchical structures also follow precisely the same hierarchical processing
principles as fixed physical hierarchical structures. This capability can be
used heavily in extending SQL’s hierarchical processing to XML and legacy
databases.
Divide and Conquer the Hierarchical Processing Problem
The “M” in XML stands for Markup
and that was what XML was designed to handle. The additional use of XML for
database data was an afterthought. Database data use is more fixed than
Markup data. Markup data requires user navigation to get the full flexible use
out of Markup data. Database data being more fixed with a more specific use does
not need to be navigated by the user; it can be accessed transparently with no
user navigation required. This is known as navigationless access.
Unfortunately, this difference in use has not yet been recognized and utilized.
Even more of a concern is that database data processed as Markup data can
produce incorrect results. By making this important distinction and limiting
XML’s database processing to fixed hierarchical processing allows its
processing to operate navigationlessly. This also allows it to perform many
advanced full hierarchical processing capabilities not possible or practical
with user navigation.
SQL Hierarchical Data Structure Modeling
In the SQL Structure Definition in
Figure 1, the Left Join operation preserves the left side argument over the
right side. This means node A can exist even if there are no matching node B
items, but node B can not exist without matching node A items. The SQL
processing continues left to right defining the hierarchical structure. The ON
clause specifies the link data points between nodes; this is why node C is
linked to node B and not node A. Notice in the SQL Structure Definition that
nodes B and D are both linked back to node A so that node A starts two separate
pathways. Each ON clause only operates locally at its specific use point and
downward because the left argument side is always preserved with Left Outer
Joins. The SQL WHERE clause does not have this local narrow range of effect;
its global effect allows it to filter the entire hierarchical structure. SQL
WHERE clause filtering can be added to the end of the SQL Structure Definition
below. The ON clause filtering is the same as XPath filtering and the SQL WHERE
clause is the same as the XQuery WHERE Filtering operation.
The SQL Structured Definition
shown in Figure 1 can be specified in an SQL Query to be directly processed by
the SQL processor. The Hierarchical Structure is defined by the Left Join
syntax and its hierarchical operation is specified by the associated semantics.
The SQL Structure Definition can also be named and defined in an SQL view for
easy use and reuse. This is shown later in Figure 4.

Figure 1 Hierarchical Data Modeling Produces Hierarchical Rowset
Interpreting Hierarchical Rowsets
Figure 1 also demonstrates a number of the most basic
hierarchical processing attributes produced in ANSI SQL. These attributes are
hierarchical data preservation from the left join and variable length path
creation with nulls inserted in the rowset to keep them aligned properly. This
is shown in the Structured Rowset above where the two sibling legs BC and DE
are independently represented at different variable lengths. The shortened null
terminated legs show that hierarchical preservation is also working; otherwise
they would be totally missing.
Mapping SQL to Hierarchical Processing at a Conceptual Level
In mapping SQL to and from hierarchical processing,
relational tables and XML elements are treated as nodes. Relational columns,
XML element strings and XML element attributes are treated as fields in data
nodes. Figure 2 below demonstrates SQL’s high level hierarchical processing
using SQL’s SELECT,
FROM, WHERE syntax and their intuitive hierarchical structured operations. These
are: input data and its hierarchical SQL modeled structure specified by the
FROM clause; output data selection specified by the SELECT clause which
indicates the hierarchically related nodes to be returned and their data and order;
and the data filtering specified in the WHERE clause which hierarchically
filters the data following its modeled hierarchical structure. These
operations used together will hierarchically process the input data and
automatically produce a hierarchical structured XML correctly representing the
processed results.
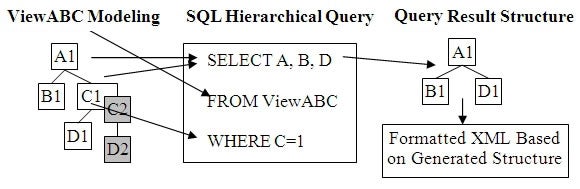
Figure 2: SQL Hierarchical Query Specification and Operation Overview
In Figure 2 you can notice that the SQL user can continue to
use the same SQL, but visualize the data structures as hierarchical and the
operation as being performed hierarchically at a high conceptual level to
produce hierarchical structures. These will be automatically converted to its
hierarchical XML structure unless overridden. The Query Result Structure in
Figure 2 demonstrates the hierarchical operation of node promotion. Notice that
the unselected nodes are removed from query result.
Querying Multipath Hierarchical Data Structures
The examples used so far have used multipath processing
where queries reference multiple pathways in the accessed hierarchical
structure. The processing of these multipath queries is not generally possible
today because they require special hierarchical processing to get correct
hierarchical results.
The ON clause covered earlier is a linear single path
qualification that is used during structure definition and creation where it
can control only the path it is on. The WHERE clause data filtering and data
qualification is logically applied after the entire structure has been created
and can affect the entire structure such that data qualification based on one path
can affect data qualification on another Path. This is because every node is
related to every other node in a hierarchical structure. This full nonlinear
hierarchical qualification is not designed or made up. It is standard
processing for nonlinear hierarchical processing based on naturally occurring
hierarchical principles. These principles have been utilized as far back as the
original hierarchical databases. And now with relational databases they are automatically
performed naturally when the data is modeled hierarchically proves their
inherent technology is correct. XML database products today are lacking this
level of principled hierarchical processing.
This hierarchical data filtering is a new capability for the
XML industry. Figure 3 indicates how it works. You can notice how the relational
rowset and its associated hierarchical structure are related. In this example,
the WHERE clause is pointing to node C in the Data Qualification Flow diagram
to demonstrate the data filtering directions taking off from node C in
different directions. If this node is selected for output, all of its
associated node occurrences are also qualified, up, down, and around as shown by
the arrows in the Data Qualification flow. This happens automatically because
the entire row is qualified. Notice how the unqualified row is not output. The
darker cells are qualified and output.
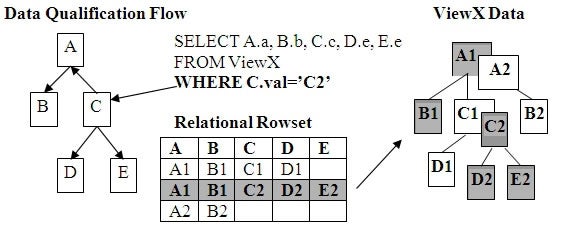
Figure 3: WHERE Clause Data Multipath Qualification Flow
Joining Structures Hierarchically
Figure 4 below represents the processing of a query that is
invoked by a query dynamically joining two hierarchical structures represented
by their view names RDBV and XMLV. In the same way that the hierarchical data
modeling was performed a node at time using Left Outer Joins in Figure 1 to
define hierarchical structures, hierarchical structures defined in SQL views
can also be joined by Left Outer Joins producing a hierarchical superstructure.
In this example, the left Relational structure is joined over the right XML structure
linked by its ON clause join criteria at a high conceptual level as
demonstrated in Figure 4. The ON clause takes on added importance by
unambiguously specifying the link points in each structure being hierarchically
joined. This is shown by the diagram of the joined structures to the right of
the SQL Processor box in Figure 4. The X node box in this diagram is dashed
indicating it is not selected for output and will be removed from output.
The ON clause was introduced in SQL-92 to replace the WHERE
clause’s join use for a more precise join control geared more for local control
at the join point. The ON clause operates during structure creation while the
WHERE clause operates after structure creation affecting the entire structure
hierarchically as a whole. This is a huge difference between the WHERE and ON
operation not generally realized and enables much of SQL’s hierarchical
capabilities.
This example in Figure 4 also demonstrates a heterogeneous
join of structures by hierarchically joining a relational structure over an XML
Structure. Non relational structures such as XML and legacy hierarchical
structures such as IBM’s IMS require their own view definition to capture their
specific set of metadata needed for their processing. This is indicated in the
XML Definition Processing box in this example. This information is used in the
Service Request for XML box when XML access is needed by the SQL Processor. The
XML Definition Process will also automatically generate a standard SQL
hierarchical view that specifies the non relational structure’s structure as a
standard SQL hierarchical structure view as shown. This allows the joined
heterogeneous structures to be hierarchical joined seamlessly using standard
SQL sequence of Left Outer Joins.
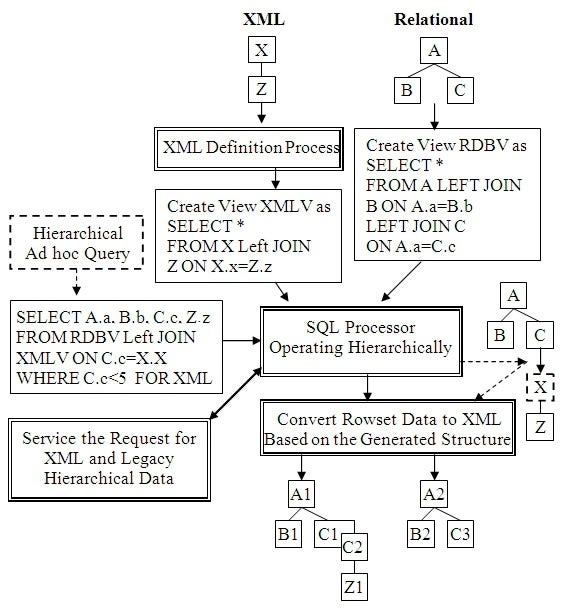
Figure 4: SQL Multi Structure Heterogeneous Hierarchical Join
In this example the relational view is a logical view and
the XML view is a physical view. The relational logical view is constructed
while the XML physical view is already constructed and is just defined
recording its structure information. Joining and processing physical and
logical structures does not present an impedance mismatch problem because they
both follow the same set of hierarchical processing principles and rules.
Conclusion
In the implementation of the prototype that proved the
capability of the design modeled in Figure 4, the SQL processor’s hierarchical rowset
results were converted to an XML hierarchical structure as shown. This design
kept the ANSI SQL processor unmodified, proving that it could indeed operate
fully hierarchically beyond current XML processors hierarchical capabilities.
This design could be improved in efficiency if the external processing additions
shown were integrated directly into the SQL processor. The ANSI SQL
Hierarchical XML Processor prototype can be tested at www.adatinc.com/demo.html.