
Synopsis: Learn how the appropriate use of attribute member Value can support the selection and delivery of enterprise data in a more focused and consumer-friendly manner. Join BI Architect Bill Pearson in a hands-on examination of the attribute member Value property and its underlying settings in Analysis Services.
Introduction
In Dimensional Model Components: Dimensions Parts I and II, we introduced the dimensional model in general, noting its wide acceptance as the preferred structure for presenting quantitative and other organizational data to information consumers. We then began our examination of dimensions, the analytical “perspectives” upon which the dimensional model relies in meeting the primary objectives of business intelligence, including its capacity to support:
- the presentation of relevant and accurate information representing business operations and events;
- the rapid and accurate return of query results;
- “slice and dice” query creation and modification;
- an environment wherein information consumers can pose questions quickly and easily, and achieve rapid results datasets.
We learned, in Dimensional Model Components: Dimensions Parts I and II, that dimensions form the foundation of the dimensional model. They represent the perspectives of a business or other operation, and reflect the intuitive ways that information consumers need to query and view data. We noted that we might consider dimensions as nouns that take part in, are acted upon by, or are otherwise associated with, the verbs (or actions / transactions undertaken by the business) that are represented by the facts or measures contained within our business intelligence systems.
We discovered in earlier articles that, within the Analysis Services model, database dimensions underlie all other dimensions, whose added properties distinguish them from the database dimensions they reference, within the model. Each dimension within our model contains one or more hierarchies. As we learn in other articles of this series, two types of hierarchies exist within Analysis Services: attribute hierarchies and user (sometimes called “multi-level”) hierarchies. For purposes of this article, the term “attribute” means the same thing as “attribute hierarchy”. (We examine user hierarchies, to which we will simply refer as “hierarchies,” in other articles specifically devoted to that topic.)
To extend the metaphor we used earlier in describing dimensions as nouns and measures as verbs, we might consider attributes as somewhat similar to adjectives. That is, attributes help us to define with specificity what dimensions cannot define by themselves. Dimensions alone are like lines in geometry: they don’t define “area” within multidimensional space, nor do they themselves even define the hierarchies that they contain. A database dimension is a collection of related objects called attributes, which we use to specify the coordinates required to define cube space.
Within the table underlying a given dimension (assuming a more-or-less typical star schema database) are individual rows supporting each of the members of the associated dimension. Each row contains the set of attributes that identify, describe, and otherwise define and classify the member upon whose row they reside. For instance, a member of the Patient dimension, within the Analysis Services implementation for a healthcare provider, might contain information such as patient name, patient ID, gender, age group, race, and other attributes. Some of these attributes might relate to each other hierarchically, and, as we shall see in other articles of this subseries (as well as within other of my articles), multiple hierarchies of this sort are common in real-world dimensions.
Dimensions and dimension attributes should support the way that management and information consumers of a given organization describe the events and results of its business operations. Because we maintain dimension and related attribute information within the database underlying our Analysis Services implementation, we can support business intelligence for our clients and employers even when these details are not captured within the system where transaction processing takes place. Within the analysis and reporting capabilities we supply in this manner, dimensions and attributes are useful for aggregation, filtering, labeling, and other purposes.
Having covered the general characteristics and purposes of attributes in Dimensional Attributes: Introduction and Overview Parts I through V, we then fixed our focus upon the properties underlying them, based upon the examination of a representative attribute within our sample cube. We then continued our extended examination of attributes to yet another important component we had touched upon earlier, the attribute member Key, with which we gained some hands-on exposure in practice sessions that followed our coverage of the concepts. In Attribute Member Keys – Pt I: Introduction and Simple Keys and Attribute Member Keys – Pt II: Composite Keys, we introduced attribute member Keys in detail, continuing our recent group of articles focusing upon dimensional model components, with an objective of discussing the associated concepts, and of providing hands-on exposure to the properties supporting them.
As a part of our exploration of attribute member Keys, we first discussed the three attribute usage types that we can define within a containing dimension. We then narrowed our focus to the Key attribute usage type (a focus that we developed, as we have noted, throughout Attribute Member Keys – Pt I: Introduction and Simple Keys and Attribute Member Keys – Pt II: Composite Keys), discussing its role in meeting our business intelligence needs. We next followed with a discussion of the nature and uses of the attribute Key from a technical perspective, including its purpose within a containing dimension within Analysis Services.
In Attribute Member Keys – Pt I: Introduction and Simple Keys and Attribute Member Keys – Pt II: Composite Keys, we introduced the concepts of simple and composite keys, narrowing our exploration in Part I to the former, where we reviewed the Properties associated with a simple key, based upon the examination of a representative dimension attribute, Geography, within our sample UDM. In Part II, we revisited the differences between simple and composite keys, and explained in more detail why composite keys are sometimes required to uniquely identify attribute members. We then reviewed the properties associated with a composite key, based upon the examination of a representative dimension attribute, Date, also within our sample UDM.
In Attribute Member Names, we examined the attribute member Name property, which we had briefly introduced in Dimensional Attributes: Introduction and Overview Part V. We examined the details of the attribute member Name, and shed some light on how they might most appropriately be used without degrading system performance or creating other unexpected or undesirable results.
In this article, we will examine the “sister” attribute member Value property, which we introduced along with attribute member Name in Dimensional Attributes: Introduction and Overview Part V. Similar to our examination of attribute member Name, we will examine the details of Value. Our focus will also similarly be upon its appropriate use in providing support for the selection and delivery of enterprise data in a more focused and consumer-friendly manner, without the unwanted effects of system performance degradation, and other unexpected or undesirable results, that can accompany the uninformed use of the property.
Our examination will include:
- A review of the nature of the attribute member Value property, and its possible roles in helping to meet the primary objectives of business intelligence.
- A review of the nature and uses of the attribute member Value from a technical perspective, including its purpose within its containing dimension within Analysis Services.
- A discussion surrounding some of the differences between attribute Value and Key properties.
- A review of the settings associated with the Value property, based upon the examination of a representative dimension attribute within our sample UDM.
Attribute Member Values
As we have learned, attributes serve as the foundation for our dimensions and cubes. To review, we discovered in Attribute Member Keys – Pt I: Introduction and Simple Keys that each attribute, typically based (via the Data Source View) upon a single column (or a named calculation) within the associated, underlying dimension table, falls into one of three possible usage roles, Regular, Parent, and Key. We then focused upon the attribute member Key, examining our subject from the perspective of both a simple key and a composite key. As we noted there, the attribute member Key is critical to the identification of unique attribute members within Analysis Services. The Key, we learned, is specified within the KeyColumns setting, within the Source group of a dimension’s Attribute properties. (We overviewed the Source properties in my Database Journal article Dimension Attributes: Introduction and Overview, Part V.)
Just as attribute members are assigned a Key (be it simple or composite) to uniquely identify them, members can be assigned a Value, just as they can a Name, as we noted in Attribute Member Names. And just as a descriptive Name is often more consumer – friendly (and not necessarily a mere luxury), yet another alternative value for an attribute can offer even more support for the selection and delivery of enterprise data in a more focused and consumer-friendly manner. We can even use attribute member Values as an alternative sort criterion (which is most often determined by the Key).
We do not have to assign a Value. If we do not, Analysis Services assigns, as the attribute member Value, whatever is assigned as the default attribute member Name (NameColumn setting). If an attribute member Name is not assigned, and therefore has a default of the attribute member Key value, then the default for the attribute Value becomes the Key value (KeyColumns setting) for the same attribute member.
An arrangement where only Name and Key values are present might be quite appropriate for some business scenarios. For that matter, having only Key values specified in the attribute member property settings might be perfectly adequate when, say, information consumers would be certain to recognize part or serial numbers, or other designations, and do not need “English” names. But as we noted in Attribute Member Names, a Name comes in handy for both analysis and reporting. A third, alternate value can be just as useful. Moreover, and, even in cases where everyone does not need either, or both, of the Name or Value alternatives, each (or both) can certainly be suppressed (as in a report), etc., except for scenarios within which benefit is obtained from its (their) presence. (I have written reports where the consumer could make the choice at runtime to hide or display the Value, Name, Key or combination of any of these, or even to select Value, Name, Key or combination of any of these to populate the associated parameter picklist each time the report is executed, among other options).
NOTE: I introduce and examine the intrinsic MEMBER_KEY, MEMBER_NAME and MEMBER_VALUE properties (which are derived from the KeyColumns, NameColumn and ValueColumn property settings, respectively) from the perspective of their use within MDX queries, in my articles Intrinsic Member Properties: The MEMBER_KEY Property, Intrinsic Member Properties: The MEMBER_NAME Property, and Intrinsic Member Properties: The MEMBER_VALUE Property, respectively. Both articles are members of my MDX Essentials series at Database Journal.
In our use of the attribute member Value property (which references the underlying ValueColumn property) to support the return of yet another value for the attribute member with which it is associated, we can provide our employers and clients an alternate value that can be useful in a host of different applications, and can be leveraged in activities that range from generating simple lists to supporting sophisticated presentations. The attribute member Value can, for example, be a particularly effective component, as we have seen to be the case with the attribute member Name, when we need to provide parameter picklist support and the like.
We will gain hands – on exposure to attribute member Value in the practice session that follows. Before we get started working within a sample cube clone, we will need to prepare the local environment for the practice session. We will take steps to accomplish this within the section that follows.
Preparation: Locate and Open the Sample Basic UDM Created Earlier
In Dimensional Model Components: Dimensions Part I, we created a sample basic Analysis Services database within which to perform the steps of the practice sessions we set out to undertake in the various articles of this subseries. Once we had ascertained that the new practice database appeared to be in place, and once we had renamed it to ANSYS065_Basic AS DB, we began our examination of dimension properties. We continued with our examination of attributes within the same practice environment, which we will now access (as we did within Dimensional Model Components: Dimensions Part I and Dimensional Attributes: Introduction and Overview Parts I through V) by taking the following steps within the SQL Server Business Intelligence Development Studio.
NOTE: Please access the Analysis Services database which we prepared in Dimensional Model Components: Dimensions Part I (and have used in subsequent articles) before proceeding with this article. If you have not completed the preparation to which I refer, or if you cannot locate / access the Analysis Services database with which we worked in the referenced previous articles, please consider taking the preparation steps provided in Dimensional Model Components: Dimensions Part I before continuing, and prospectively saving the objects with which you work, so as to avoid the need to repeat the preparation process we have already undertaken for subsequent related articles within this subseries.
1. Click Start.
2. Navigate to, and click, the SQL Server Business Intelligence Development Studio, as appropriate.
We briefly see a splash page that lists the components installed on the PC, and then Visual Studio .NET 2005 opens at the Start page.
3. Close the Start page, if desired.
4. Select File –> Open from the main menu.
5. Click Analysis Services Database … from the cascading menu, as shown in Illustration 1.
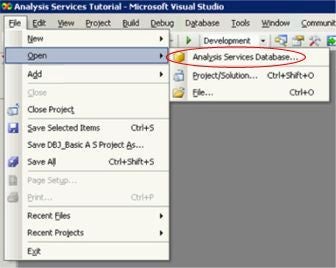
Illustration 1: Opening the Analysis Services Database …
The Connect to Database dialog appears.
6. Ensuring that the Connect to existing database radio button atop the dialog is selected, type the Analysis Server name into the Server input box (also near the top of the dialog).
7. Using the selector just beneath, labeled Database, select ANSYS065_Basic AS DB, as depicted in Illustration 2.
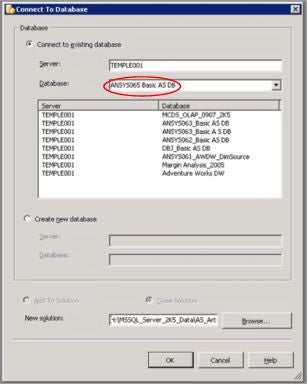
Illustration 2: Selecting the Basic Analysis Services Database …
8. Leaving other settings on the dialog at default, click OK.
SQL Server Business Intelligence Development Studio briefly reads the database from the Analysis Server, and then we see the Solution Explorer populated with the database objects. Having overviewed the properties of dimension attributes in previous articles, we will continue to get some hands-on exposure to the Value property for an example dimension attribute member, from within our practice UDM.