


Introduction
Microsoft introduced Azure SQL Data Warehouse, a new enterprise-class, elastic petabyte-scale, data warehouse service that can scale according to organizational demands in just few minutes. In my last article of the series, I talked about the different types of tables we can create in SQL Data Warehouse and how it impacts performance and best practices around them. I also demonstrated how to get started with creating a SQL Data Warehouse database and to connect to it from SQL Server Management Studio (SSMS). In this article, I am going to talk in detail about round-robin and distributed tables, and how to create them. I will also discuss how partitioning works in SQL Data Warehouse and look at the impact of choosing the right distribution key. I will also cover PolyBase in detail and how you can leverage it to easily and quickly import or export data from SQL Data Warehouse.
Working with Tables and Data in SQL Data Warehouse
Here is a script to create a table in SQL Data Warehouse. (I have removed most of the columns of the table here to make it more readable; you need to remove the dot-dot or replace it with the rest of the other columns definition). If you notice, there is no ON clause when creating a table in SQL Data Warehouse; this means unlike SMP SQL Server where we need to create file groups and specify a file group when creating a table for instructing SQL Server where to store the data, in SQL Data Warehouse the platform itself takes care of where to store data – storage across multiple distributed file groups or distributions.
We also didn’t specify any detail on how data should be distributed and what index should be created. In that case, by default the table is created with clustered columnstore index and data is distributed using the round-robin distribution method across all distributions. You can verify this by scripting out the created table from Object Explorer, as shown below.
CREATE TABLE [dbo].[DimProduct1]
(
[ProductKey] [int] NOT NULL,
[ProductAlternateKey] [nvarchar](25) NULL,
………………………………..
[StartDate] [datetime] NULL,
[EndDate] [datetime] NULL,
[Status] [nvarchar](7) NULL
)
GO
Clustered columnstore index
When you want to override the default behavior, for example when you want to create a table with a hash distributed key or want to have a rowstore index or want to create a heap table instead, you need to explicitly use the WITH clause as shown below. In the example below, the table is created with columnstore index and data is distributed by applying the hash function on the ProductKey column values. If you want to create table as heap, you need to replace CLUSTERED COLUMNSTORE INDEX with HEAP.
CREATE TABLE [dbo].[DimProduct]
(
[ProductKey] [int] NOT NULL,
[ProductAlternateKey] [nvarchar](25) NULL,
………………………………..
[StartDate] [datetime] NULL,
[EndDate] [datetime] NULL,
[Status] [nvarchar](7) NULL
)
WITH
(
DISTRIBUTION = HASH ( [ProductKey] ),
CLUSTERED COLUMNSTORE INDEX
)
GOPartitioning a Table
Partitioning plays an important role in optimizing query performance as well as optimizing load and delete\archive data processes (I discussed partitioning in SQL Server in this article series, which works in a similar way in SQL Data Warehouse).
Unlike in SQL Server, where you need to first a create partition function and then partition scheme before creating a partitioned table, here in SQL Data Warehouse you just need to specify a partitioning strategy (partitioning key, range type and partition boundaries), as you can see below, within the WITH clause.
The table below creates a table with partitions using OrderDateKey as the partitioning key column, right range and yearly partition boundaries.
CREATE TABLE [dbo].[FactInternetSales]
(
[ProductKey] [int] NOT NULL,
[OrderDateKey] [int] NOT NULL,
[DueDateKey] [int] NOT NULL,
[ShipDateKey] [int] NOT NULL,
[CustomerKey] [int] NOT NULL,
[PromotionKey] [int] NOT NULL,
[CurrencyKey] [int] NOT NULL,
[SalesTerritoryKey] [int] NOT NULL,
[SalesOrderNumber] [nvarchar](20) NOT NULL,
[SalesOrderLineNumber] [tinyint] NOT NULL,
[RevisionNumber] [tinyint] NOT NULL,
[OrderQuantity] [smallint] NOT NULL,
[UnitPrice] [money] NOT NULL,
[ExtendedAmount] [money] NOT NULL,
[UnitPriceDiscountPct] [float] NOT NULL,
[DiscountAmount] [float] NOT NULL,
[ProductStandardCost] [money] NOT NULL,
[TotalProductCost] [money] NOT NULL,
[SalesAmount] [money] NOT NULL,
[TaxAmt] [money] NOT NULL,
[Freight] [money] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) NULL,
[CustomerPONumber] [nvarchar](25) NULL
)
WITH
(
DISTRIBUTION = HASH ( [ProductKey] ),
CLUSTERED COLUMNSTORE INDEX,
PARTITION
(
[OrderDateKey] RANGE RIGHT FOR VALUES
(20000101, 20010101, 20020101, 20030101, 20040101, 20050101,
20060101, 20070101, 20080101, 20090101, 20100101, 20110101,
20120101, 20130101, 20140101, 20150101, 20160101, 20170101,
20180101, 20190101, 20200101, 20210101, 20220101, 20230101,
20240101, 20250101, 20260101, 20270101, 20280101, 20290101)
)
)
GOThere are some important considerations to take when deciding to create a partitioned table in SQL Data Warehouse. As discussed earlier, data for a table in SQL Data Warehouse is already distributed across 60 distributions internally while storing. When you create a partition on a table, data is partitioned on each distribution of the table. For example, consider you have 24 months of data for a table and you are creating monthly partitions on it, then in that case each of 60 distributions will have 24 partitions, in total 60 * 24 = 1440 partitions for all those 60 distributions.
Now as we know, clustered columnstore index breaks the data for a table in row groups (1 million rows in each row group), for better compression and optimization. In the above example, as we have 1440 partitions, this would be more beneficial if you have 1440+ millions of rows in the table. If you have less data, you can consider creating a partition on higher level, like quarterly or yearly.
Note – in the case of SQL Server you can switch-in a non-partitioned table (also called a staging table) to a partition of a partitioned table if the non-partitioned table has CHECK constraint defined. However, because there no is support for CHECK constraint in SQL Data Warehouse, you can only switch in from one partitioned table to another partitioned table (one partition at time).
Impact of Choosing the Right Distribution Key
We looked at the different things to consider when deciding about the right distribution key for a table in my earlier article. In this section, I will show you few scenarios to help you understand how a distribution key impacts the performance.
FactInternetSales table (which comes as a sample) has been distributed on ProductKey and hence it’s guaranteed that data for each specific ProductKey is going to be on the same distribution. With that assurance, we can assume that when we select data from this table and do a group by on the ProductKey, it should not move any data. This is exactly what we see with the first query in the code listing below – you can use monitoring query to look into the execution plan and currently executing queries.
With the second query, in the code listing below, we are doing a group by on CurrencyKey and because data for one specific CurrencyKey is scattered across distributions (remember, table’s distribution key column is ProductKey), it requires moving data across to produce a group by result on CurrencyKey and the same (ShuffleMoveOperation) can be seen in the execution plan for the second query below.
--No shuffle movement
select [ProductKey], sum([SalesAmount])
from [dbo].[FactInternetSales]
GROUP BY [ProductKey]![]()
No shuffle movement
--Shuffle move as grouping is done on a column
--which is not distribution hash key
select [CurrencyKey], sum([SalesAmount])
from [dbo].[FactInternetSales]
GROUP BY [CurrencyKey]
Shuffle move
The same rule applies for joining two tables as well. For example, the first query in the code listing below joins two tables on ProductKey and both tables are distributed on ProductKey and hence there is no data movement when we are joining these two tables as you can see in the figure below.
But when you join these two tables on any other column, for example in the second query I used OrderDateKey as the joining column, it required data movement and that’s what you can see in the execution plan:
SELECT fis.ProductKey, SUM(fis.SalesAmount), SUM(frs.SalesAmount) AS TotalSaleAmount
FROM FactInternetSales AS fis
INNER JOIN [dbo].[FactResellerSales] AS frs ON (fis.ProductKey=frs.ProductKey)
GROUP BY fis.ProductKey
GO![]()
OrderDateKey
SELECT fis.OrderDateKey, SUM(fis.SalesAmount), SUM(frs.SalesAmount) AS TotalSaleAmount
FROM FactInternetSales AS fis
INNER JOIN [dbo].[FactResellerSales] AS frs ON (fis.OrderDateKey=frs.OrderDateKey)
GROUP BY fis.OrderDateKey
GO
OrderDateKey
So, in summary, to identify a right distribution key you need to understand data distribution for a table and how this table is used in major workload queries. It might not be possible to consider all those workload queries, but you can consider them based on the majority or on most frequently used.
Remember, in some cases data movement might be necessary and that is not always a bad thing given that these nodes use high speed network channel for data transfer. If data transfer is evident, you should consider it for a smaller table – for which it needs to move a lesser amount of the data though.
PolyBase
PolyBase unifies data in relational data stores (Azure SQL Data Warehouse, Microsoft APS and SQL Server 2016) with non-relational data stores (Hadoop, Azure Blob storage, Azure Data Lake storage) at the query level and enables seamless querying of data by using the standard T-SQL query language without the requirement of additional manual processes, skills, or training. PolyBase can be used in SQL Server 2016, Microsoft APS and SQL Data Warehouse.

Figure 1 – PolyBase to combine and query data from both universes
PolyBase opens a new avenue to analyze data from a variety of sources in a single integrated query; on a high level, these are some of advantages of using PolyBase:
- Querying data from Hadoop – PolyBase processes Hadoop data in-place, avoiding the need for expensive ETL processes. It accepts a T-SQL query that can join local tables as well as external tables from a Hadoop cluster. It then seamlessly returns the results to the user without letting users know the nitty-gritty of the Hadoop cluster. As a user, you don’t need to understand HDFS or MapReduce (typically written in Java).
Please note, as of this writing, in SQL Data Warehouse, you can query and combine data from local tables as well as data from Azure Blob Storage and Azure Data Lake only – reading and writing to Hadoop is not yet supported in SQL Data Warehouse. - Importing data in – You can use the CREATE TABLE AS SELECT (CTAS) statement to create a local\internal table by importing the data from a non-relational data source.
- Exporting data out – With the help of PolyBase, you can export relational data out to non-relational stores for archival or for sharing it with other applications. You can leverage CREATE EXTERNAL TABLE AS SELECT to create a new external table, and export the results of the SELECT statement on the local table.
- Archiving relational data – With the help of PolyBase, you can easily offload data from your database to non-relational stores (blob, data lake and HDFS\Hadoop cluster) for archival purpose and then can use PolyBase to query the archived data without having to load it back into your database again. This helps in creating room for important data to be kept in your local relational database and at the same time not lose less important data by archiving it in non-relational stores (blob, data lake and Hadoop cluster), which can be queried anytime when needed, using PolyBase.
These are some of the use cases to use Polybase in SQL Data Warehouse:
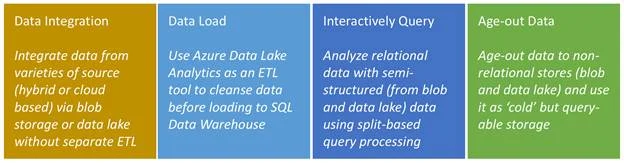
Figure 2 – PolyBase Use Cases in SQL Data Warehouse
PolyBase allows you to create an external table in SQL Data Warehouse that references the data stored in Azure Blob Storage or in Azure Data Lake – basically giving structure to the unstructured data stored in blob or in data lake. When you query this external table, PolyBase directly accesses the data in parallel, essentially bypassing the control node and bringing the data directly in to the compute nodes.
As shown in the code listing below, to start with you first need to create a database master key, which is used to encrypt a secret/access key for the credential.
Next, you need to create a database scoped credential, which is used to get authenticated while connecting to the specified data source. In the case of blob storage, you need to provide an access key for the storage account whereas in case of data lake, you need to specify an application service principal key.
Now, you need to create a data source that you want to connect to read data from or write to. Here, the data source has been created to connect to blob storage though creating a data source to connect to data lake has the same syntax.
Finally, you need to create an external file format to define the actual layout of the data referenced by an external table. I have created two external file formats below for demonstration purposes. The first one uses a comma as the column separator and assumes files are not compressed. The second one uses the multi-characters value as a column separator (this is useful in scenarios when you suspect the defined separator to be part of the data itself; defining a multi-character separator reduces the chances of collision or import failure, athough it increases the size of the output files because of additional storage space needed for additional characters storage) and assume files are compressed – there are multiple library for data compression you can choose from, I have used GZipCodec library here though.
-- Create a master key if not created already.
-- Used to encrypt the credential secret in the next step
CREATE MASTER KEY;
-- Create a database scoped credential
CREATE DATABASE SCOPED CREDENTIAL <<name of the credential>>
WITH
IDENTITY = '<<any string value>>',
SECRET = '<<Provide your Azure storage account key>>'
;
-- Create an external data source to connect to blob storage
CREATE EXTERNAL DATA SOURCE AzureStorage
WITH (
TYPE = HADOOP,
LOCATION = 'wasbs://<<containername>>@<<storageaccountname>>.blob.core.windows.net',
CREDENTIAL = <<name of the credential created above>>
);
-- Create an external file format
CREATE EXTERNAL FILE FORMAT TextFile
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR = ',')
);
-- Create an external file format
CREATE EXTERNAL FILE FORMAT TextFileWithCompression
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR = N'^|^'),
DATA_COMPRESSION = N'org.apache.hadoop.io.compress.GzipCodec'
);To see it in action, copy the content from the table below (first 4 lines of comma separated values) into a file and save it to the blob storage location (for which you created a data source above) under the Employee folder:
1,Guy,Gilbert
2,Kevin,Brown
3,Roberto,Tamburello
4,Rob,Walters
Text file
Now, create an external table and specify the structure of the data we are reading from the file (in terms columns, their data types, nullability etc.). While creating the table, you also need to specify the data source (in our case, it is used to connect to the blob storage), folder location where source file(s) exist, and file format of the actual data stored in the files. In our case, its delimited text file format though Polybase supports other file formats like RCFILE, ORC, PARQUET, etc.
Once a file is created, you can verify it in Object Explorer under the External Tables node or you can run a SELECT statement to read data from the files in blob storage via the created external table.
--Create an external table to read data from
--external source
CREATE EXTERNAL TABLE dbo.ext_Employee
(
EmployeeKey INT NOT NULL,
FirstName VARCHAR(50) NOT NULL,
LastName VARCHAR(50) NOT NULL
)
WITH (
LOCATION='/Employee/',
DATA_SOURCE=AzureStorage,
FILE_FORMAT=TextFile
);
Verify file in Object Explorer
--Read data from external source via an external table
SELECT * FROM dbo.ext_Employee
Read data from external source
An external table, like the one we created earlier, doesn’t manage the data. This means we can add additional files to the blob storage and when you read the data again from the external table using the same SELECT statement, you will get refreshed data (all the data from all files available at the time of the query execution unless you have some filter specified). To demonstrate this, I created another copy of the same file at the same location and executed the same SELECT statement against the external table. Now, as you can see we have double the count of rows (duplicate data) as we have two files with the same set of data.
--Copy more data to blob storaged
Copy Data
--Read data from external source via an external table
SELECT * FROM dbo.ext_Employee
Read Data
We learned about reading data from an external data source (in our case blob storage) in SQL Data Warehouse via external table, now if you want to import the data into an internal table – to persist it in SQL Data Warehouse, you can use the CTAS (CREATE TABLE AS SELECT) statement as shown below. Please note, this newly created table is a managed table (which gets data populated at the time of the table creation) and its data doesn’t change if there is a change in the content of the folder pointed by the source external table.
-- Using CTAS to importing data in via external table
CREATE TABLE dbo.DimEmployee2
WITH
(
DISTRIBUTION = ROUND_ROBIN,
CLUSTERED COLUMNSTORE INDEX
)
AS
SELECT * FROM dbo.ext_EmployeeThe process to export the data out from SQL Data Warehouse to the external data source (in our case blob storage) is not much different from importing it in. To export the data out, you need to use CETAS (CREATE EXTERNAL TABLE AS SELECT) to read the data out from an internal table and to write it to location pointed by the external table definition. This time, if you notice, I used the second file format, which expects the data to be in compressed format, and hence the output of the command produces compressed output files as seen in the figure below. You can also verify the table in Object Explorer under the External Tables node as shown below.
-- Create an external file format with Multi-Character delimiter
CREATE EXTERNAL TABLE dbo.ext_DimProduct
WITH (
LOCATION='/DimProduct/',
DATA_SOURCE=AzureStorage,
FILE_FORMAT=TextFileWithCompression
)
AS
SELECT * FROM [dbo].[DimProduct]
Compressed output files
--Read data from external source via an external table
SELECT * FROM dbo.ext_DimProdcut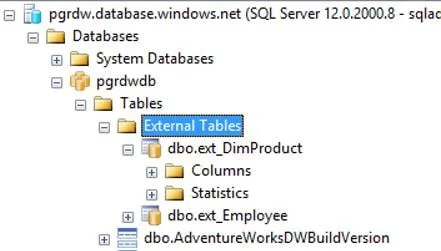
Read data from external source
Please note, the table we created above to export the data out is an external table, which doesn’t manage the data it points to. This means even if you drop this table after creating it, the data files will still be there in blob storage. You can recreate the same table pointing to the same location or you can create another table with a different name but still pointing to the same location and both will give the same result. In other words, you can have multiple external tables giving the same result if they all point to the same folder.
Conclusion
In this article, we looked at round-robin and distributed table types and how to create them. We learned about partitioning, how it works in SQL Data Warehouse and looked at the impact of choosing the right distribution key for optimized performance. I also talked in detail about PolyBase and how you can leverage it to import data in or export data out from SQL Data Warehouse very easily and quickly.
In the next article of the series, we will look at the importance of statistics in SQL Data Warehouse, how workload management works and some best practices.
Resources
Getting Started with Azure SQL Data Warehouse – Part 1
Getting Started with Azure SQL Data Warehouse – Part 2
Getting Started with Azure SQL Data Warehouse – Part 3
Design for Big Data with Microsoft Azure SQL Data Warehouse